VMware10的安装与卸载
去BIOS里面修改设置开启虚拟化设备支持(开机狂按F2或F10进入BIOS系统)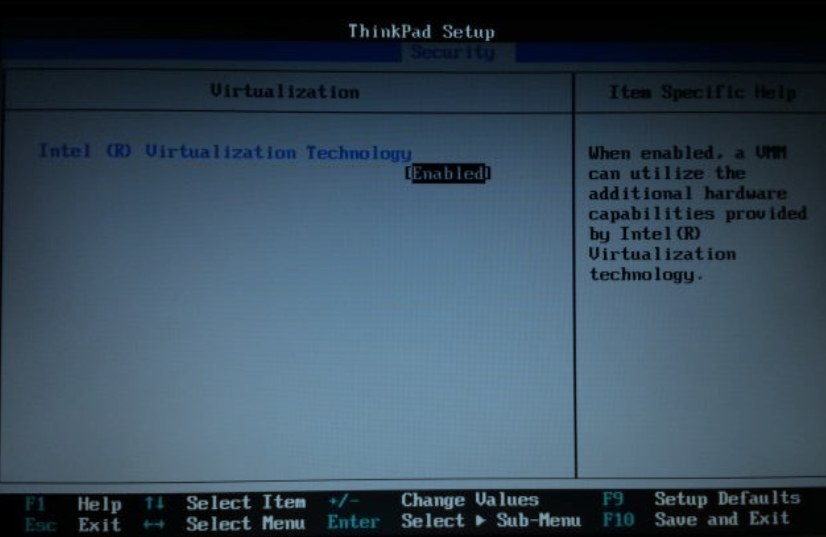
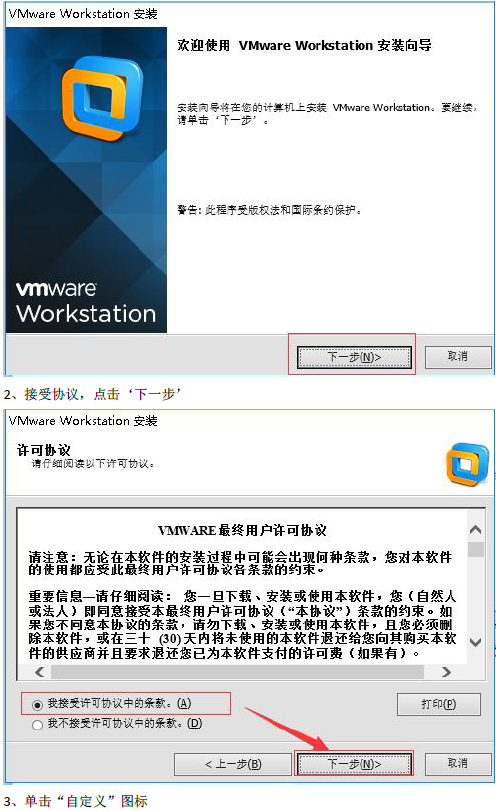
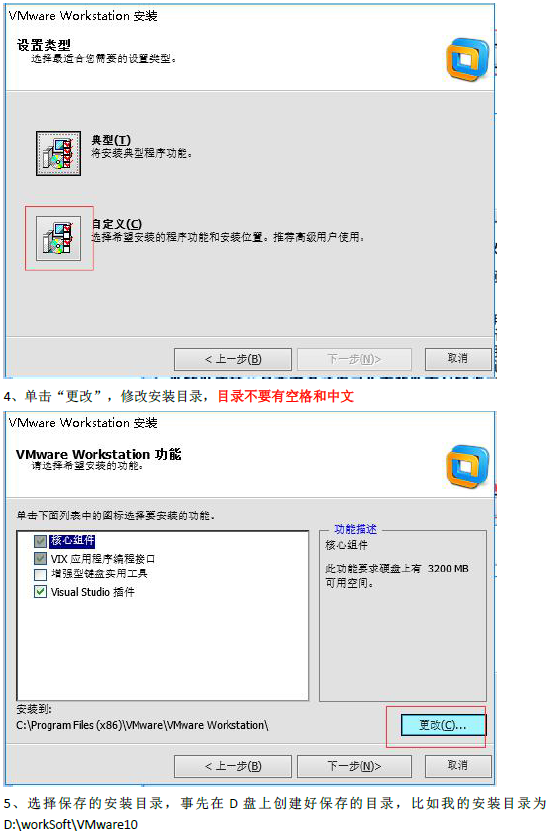
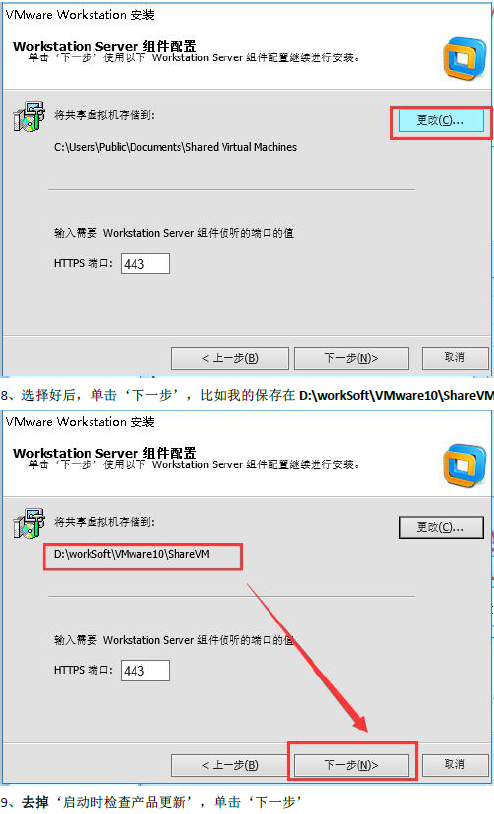
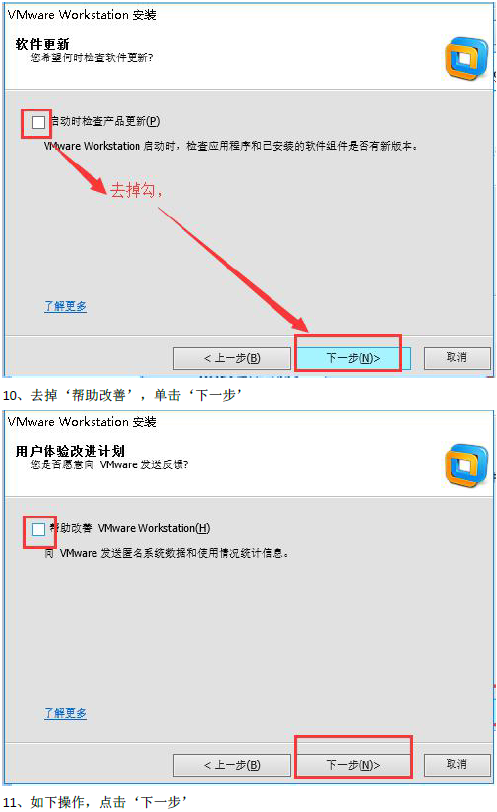
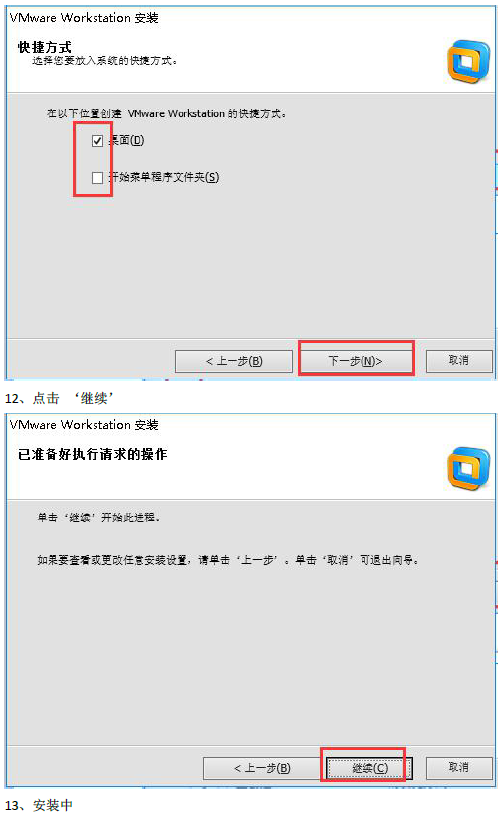
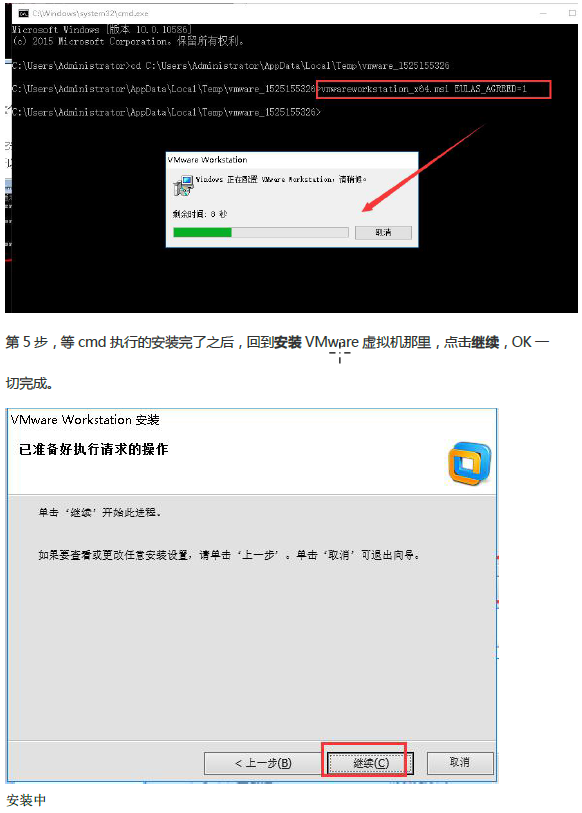
安装傻瓜式安装(一直下一步, 选择自定义安装, 取消勾选Visual Studio插件, 更改安装路径)
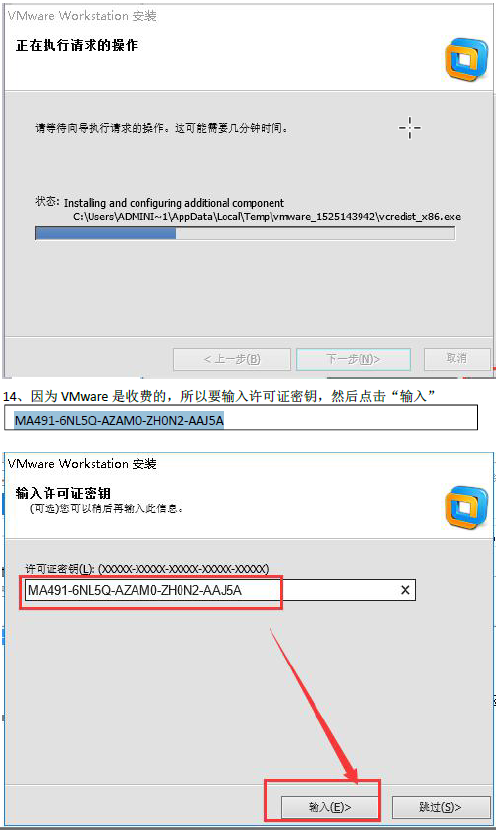
许可证秘钥
MA491-6NL5Q-AZAM0-ZH0N2-AAJ5A
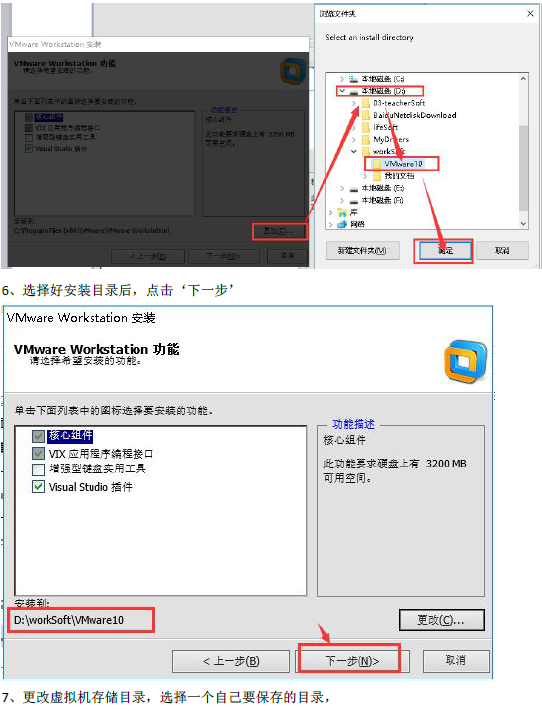

VMware安装时报错解决办法
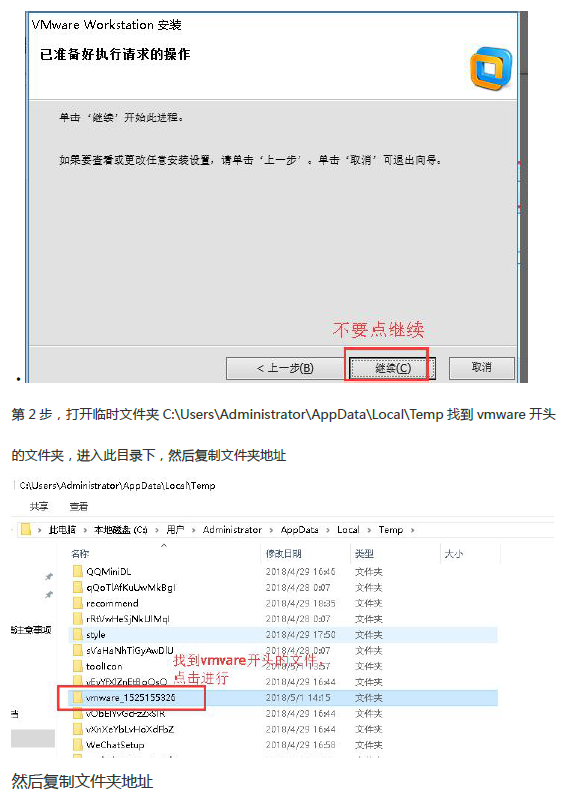


打开Windows的 程序和功能 选中右键一步一步地傻瓜式卸载
CentOS的安装
CentOS镜像下载地址
网易镜像:http://mirrors.163.com/centos/7/isos/
搜狐镜像:http://mirrors.sohu.com/centos/7/isos/
新建虚拟机配置
文件-新建虚拟机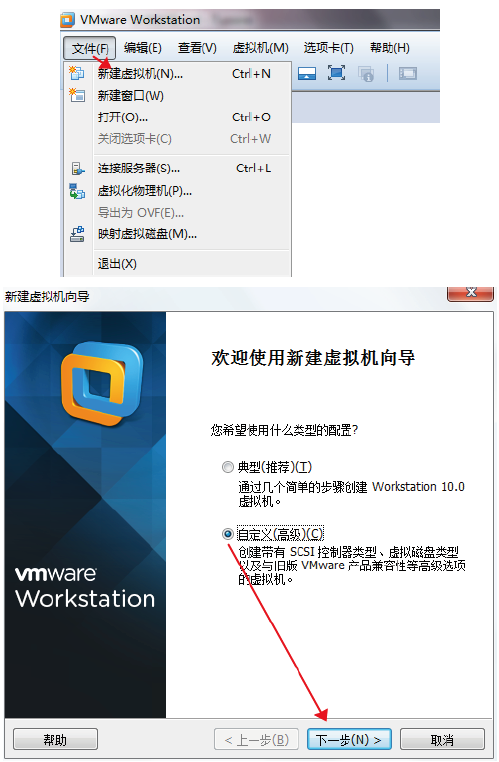
稍后安装操作系统
Linux>CentOS 64位
安装CentOS
VMware Workstation10上安装CentOS7
1.点击: 开启此虚拟机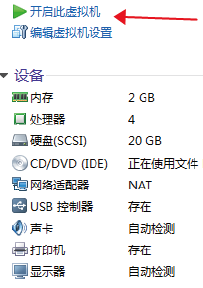
2.单击下面黑色屏幕,然后按键盘上下键 选择第一个Install CentOS7 ,再按回车键进行安装
3.等待一会,下拉选择语言: 中文
4.下面窗口项目等待一会它会自动安装好, 然后选中: 软件选择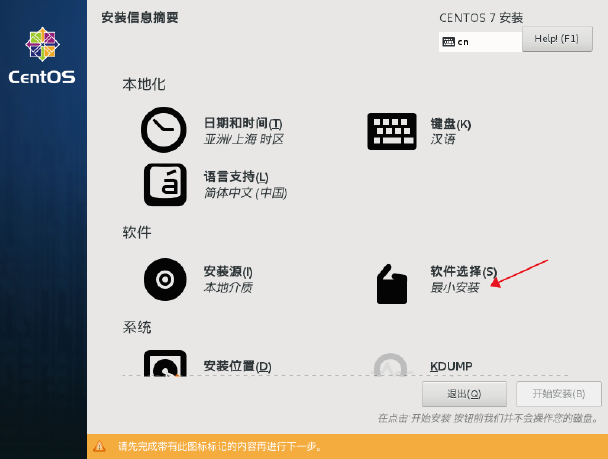
安装图形化桌面与Vim文本编辑器软件等(此步骤已经就安装了VMTools工具了)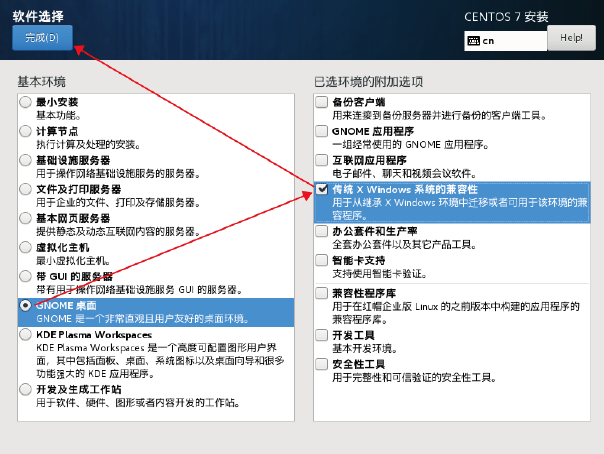
点击上面完成后,如下窗口等待一会,它需要检查软件关系,等待安装源和软件选择不是灰色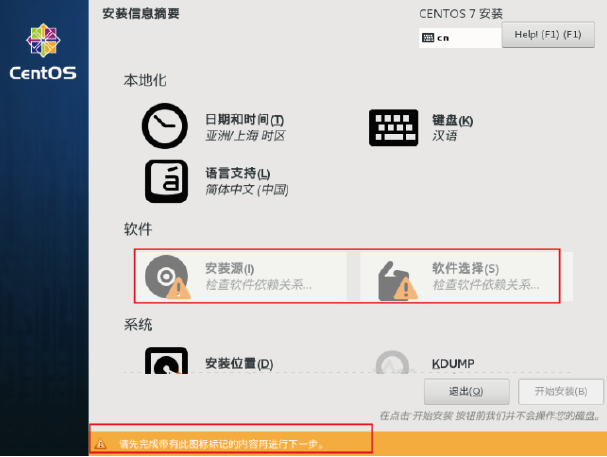
5.点击”安装位置”指定分区情况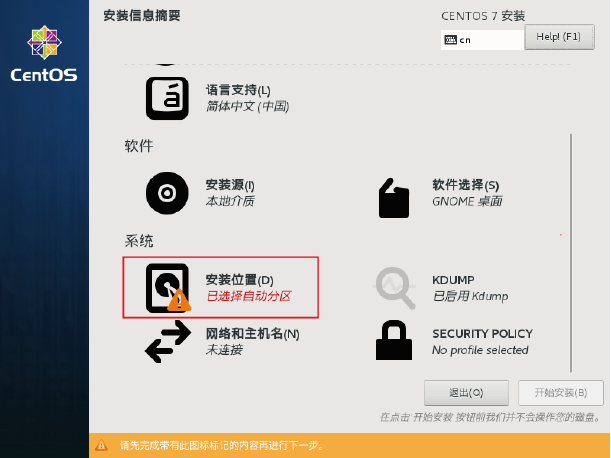
选择”我要配置分区”, 双击”完成”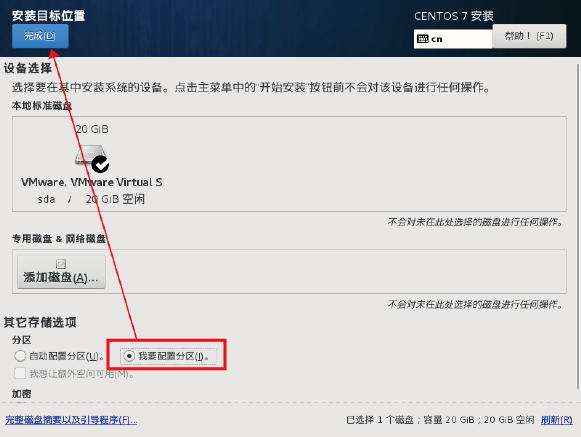
双击”点这里自动创建他们(C)” 让它自动创建分区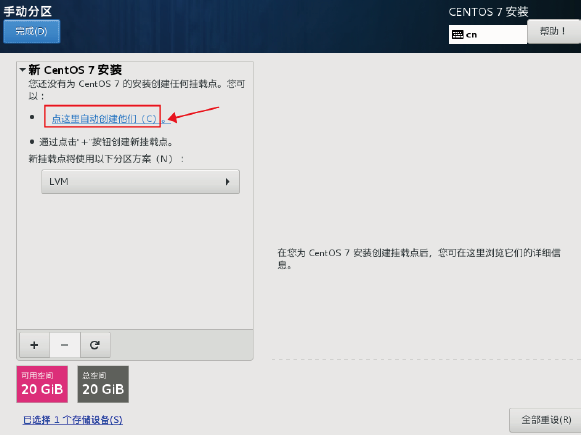
下面窗口双击”完成”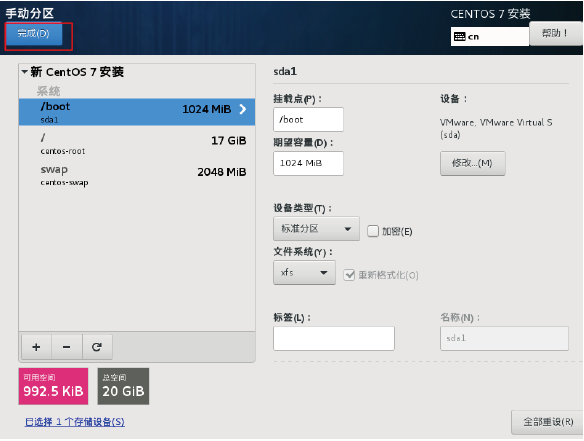
双击”接受更改”
6.双击”开始安装”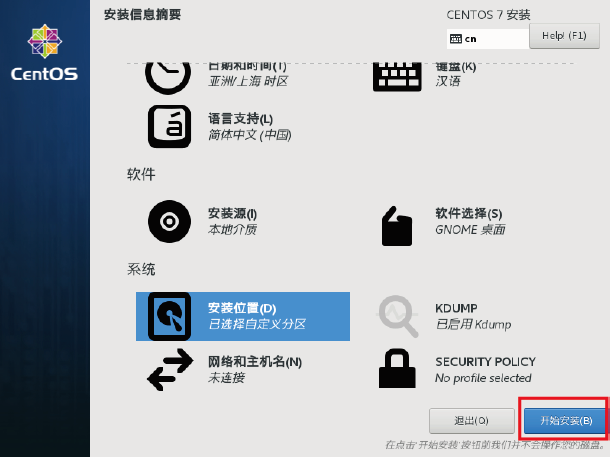
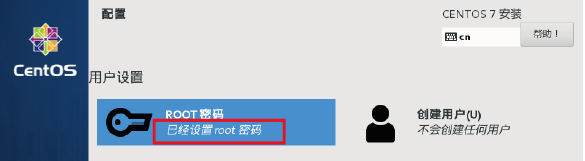
7.安装中, 安装需要等待一定时间. 安装过程中可以先设置ROOT账户密码,点击”ROOT密码”
设置ROOT账户的密码为root, 点击”完成”
8.下图表示按照完成, 点击”重启”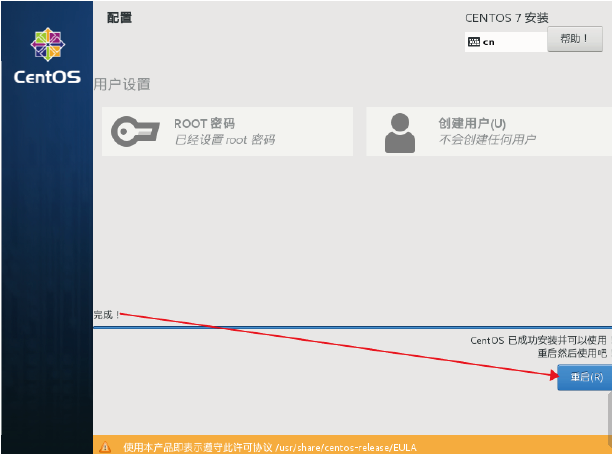
9.选择第一个, 然后按回车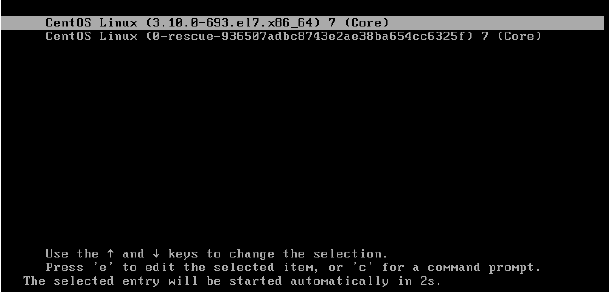
10.双击”未接受许可证”,进行接受许可
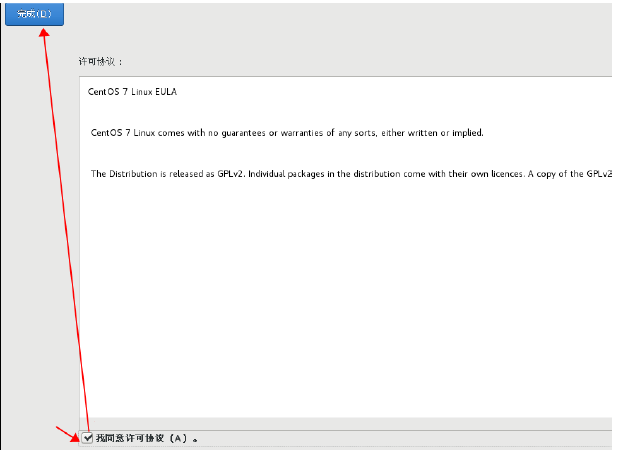
点击完成配置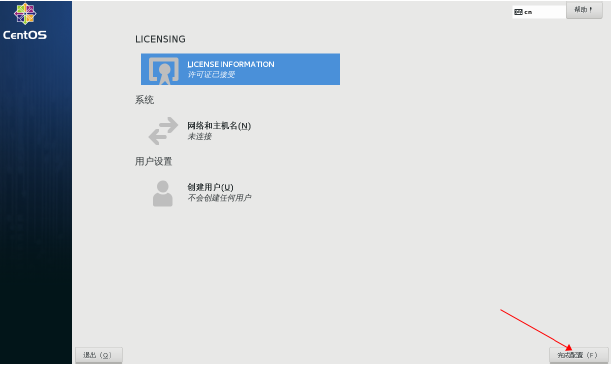
11.启动中
12.点击前进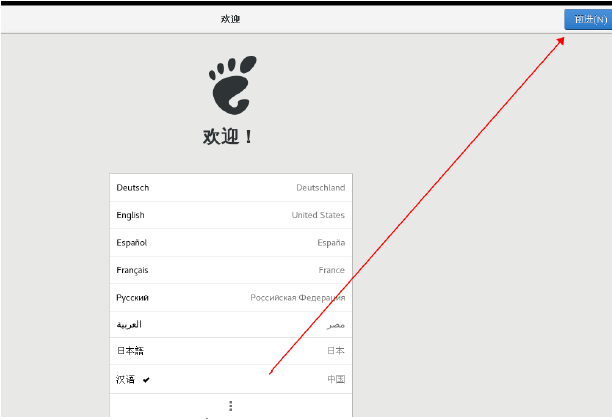
13.选择失去: 上海, 点击 前进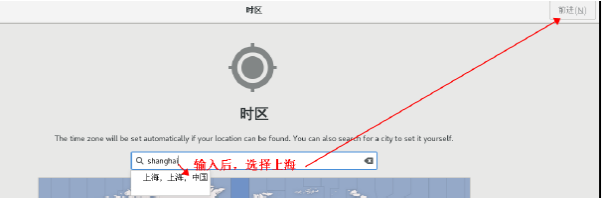
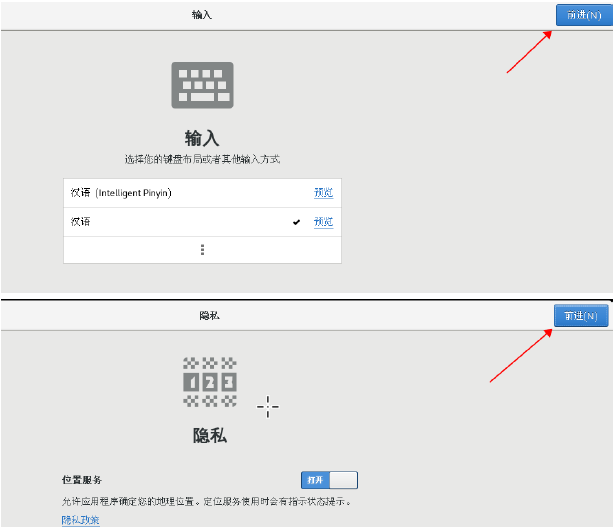
14.跳过
15.设置一个用户名parkour , 点击 前进
16.为上面parkour用户设置密码: xiaoqinyun1993 后面我们使用的账户是root/root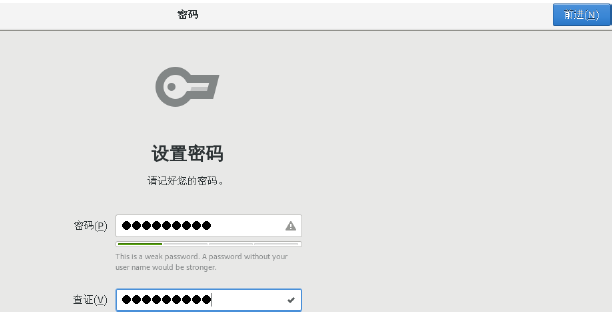
17.完成
网络配置
3.1 设置静态IP
1.右键单击打开终端后切换到root用户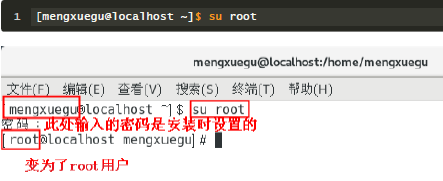
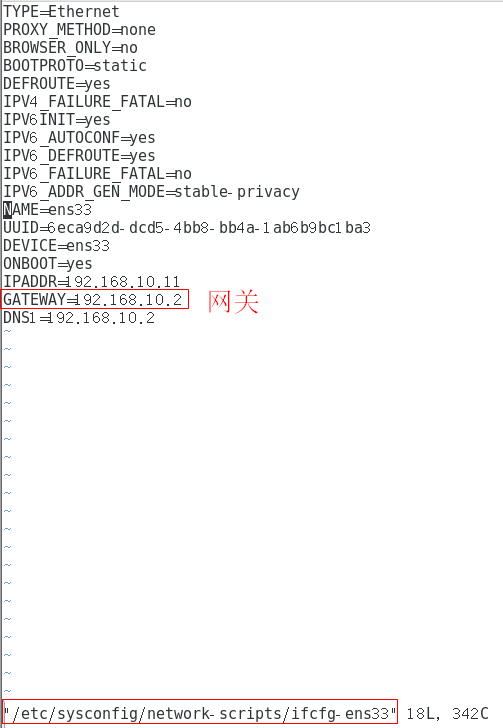
2.编辑ifcfg-ens33文件, 配置静态IP
vim /etc/sysconfig/network-scripts/ifcfg-ens33将文件的内容修改为如下的内容, :wq保存退出
3.重启网络服务
service network restart
4.查看当前IP地址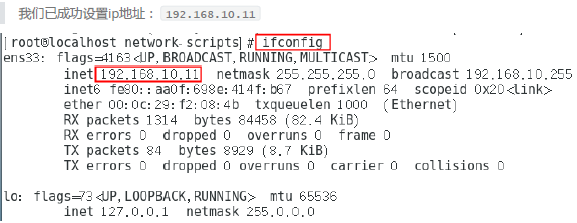
5.在虚拟机内ping外面的主机的IP, 然后在主机的cmd窗口ping虚拟机的IP, 能相互ping通说明主机和虚拟机是通的, 使用虚拟机ping www.baidu.com能ping通说明虚拟机能连外网
3.2 解决网络不通
如果上面相互ping不通, 则做如下设置
1.编辑VMware设置网络, 编辑->虚拟机网络编辑器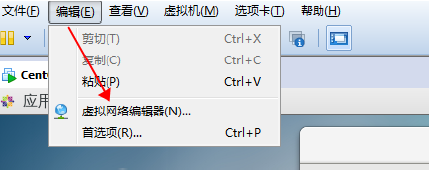
2.做如下IP设置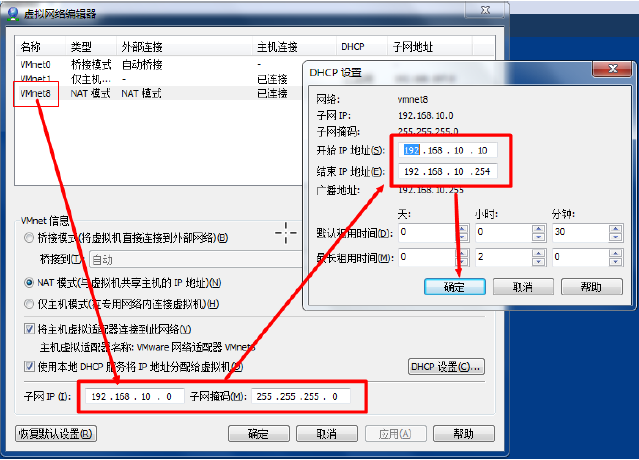
3.再重新互相ping, 能相互ping通, 并且能ping通www.baidun.com则说明通了
关闭防火墙
因为自己电脑上一直都是学习阶段, 所以将防火墙关闭. 以防后面安装程序, 主机上连接不上虚拟机上的程序. 或者软件的端口被防火墙拦截的问题
学习CentOS7时,记得要将防火墙关闭,并且设置开机禁止启动
# 关闭防火墙
systemctl stop firewalld
# 禁止开机自启
systemctl disable firewalld
# 查看防火墙状态
systemctl status firewalld解决Linux能ping通Windows主机,但主机ping不通Linux
在开启虚拟机以后,发现虚拟机可以ping通主机,但是在主机的命令终端下ping虚拟机却连接超时,原因在于主机的VMware Network Adapter VMnet8网络适配器IP设置不对,与虚拟机IP没在同一个网段。
在虚拟机的终端下输入ifconfig,查看虚拟机的ip、子网掩码、网关,如我的是192.168.10.11,255.255.255.0,192.168.10.2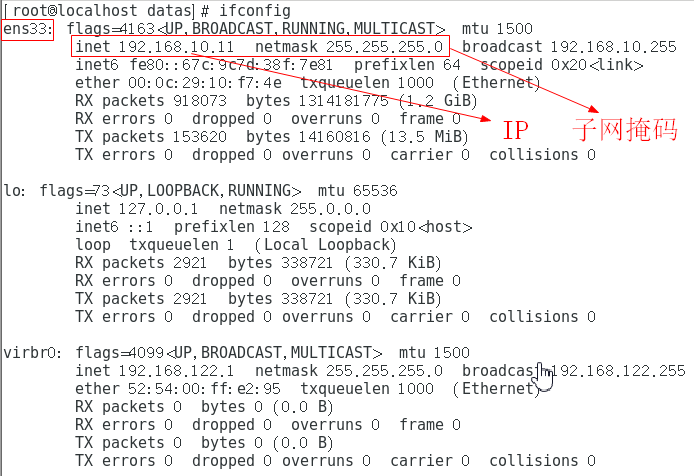
在主机的cmd下输入ipconfig,查看主机的VMware Network Adapter VMnet8的ip、子网掩码、网关,发现不在一个网段下。
于是去本机的网络与共享中心,点击更改适配器设置,点击VMware Network Adapter VMnet8,点击属性,点击Internet协议版本4(TCP/IPv4)修改属性

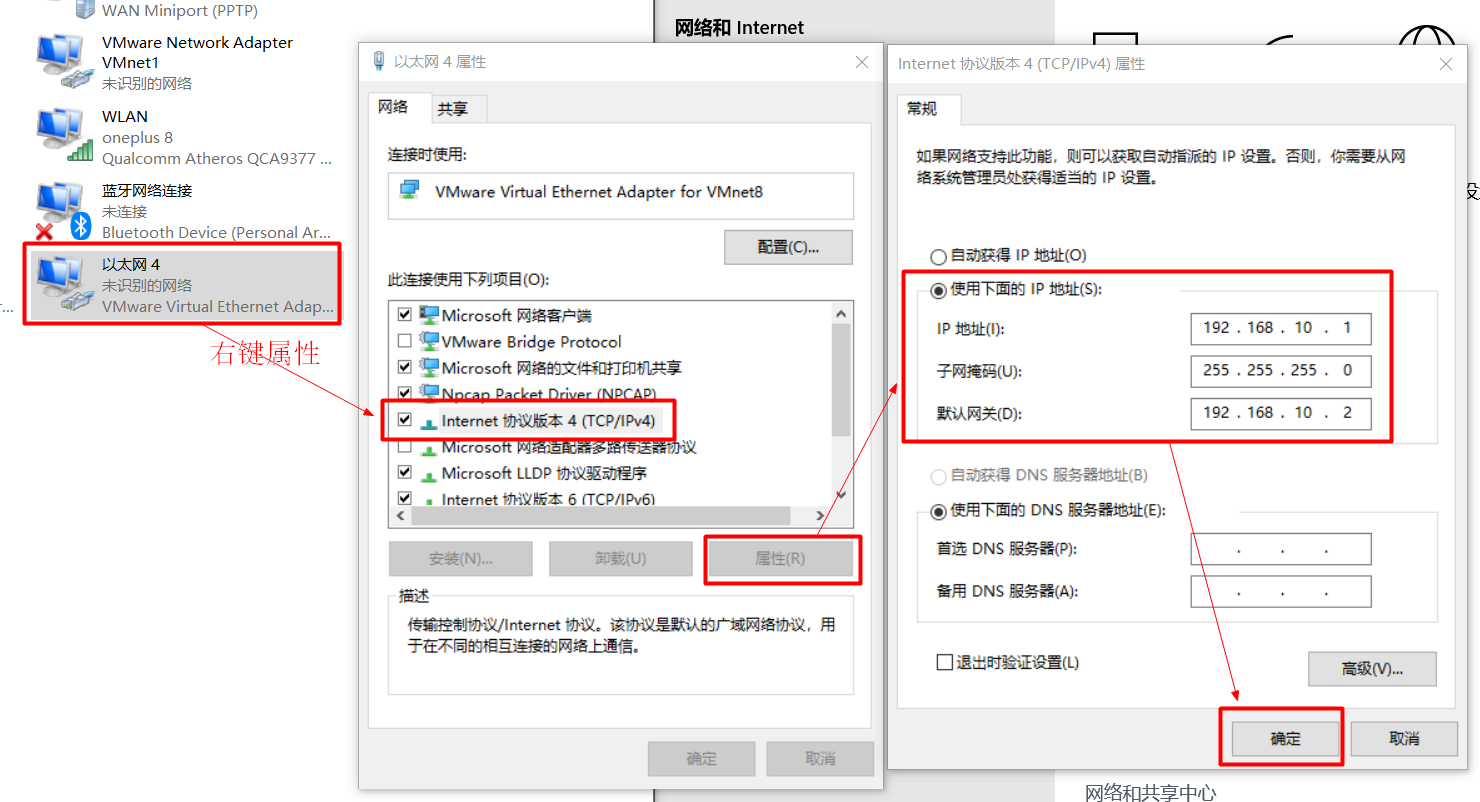


再次尝试从主机ping虚拟机,可以ping通
使用SecureCRT连接Linux
安装SecureCRT步骤,略
为什么需要使用SecureCRT远程登录Linux进行操作
Linux一般作为服务器使用,而服务器一般放在机房,你不可能在机房操作你的Linux服务器。
这时我们就需要远程登录到Linux服务器来管理维护系统。
Linux系统中是通过SSH服务实现的远程登录功能,默认ssh服务端口号为 22
新建连接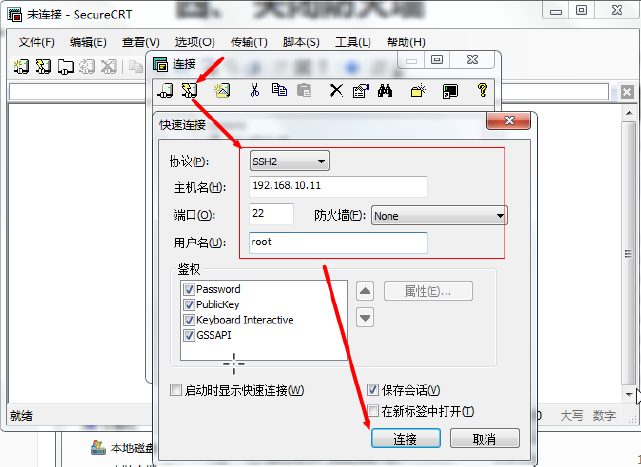
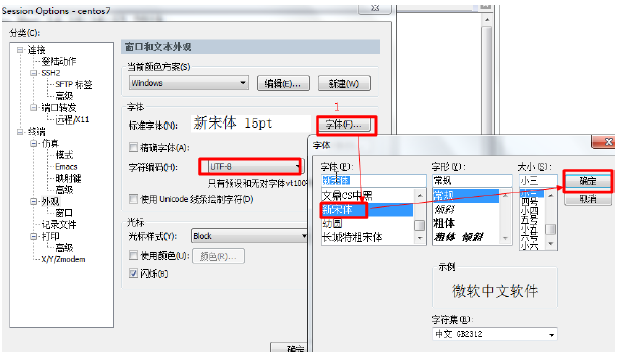
解决SecureCRT命令窗口出现中文乱码的问题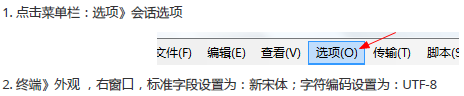
使用Xftp在windows和linux之间传输文件
安装Xftp步骤,略
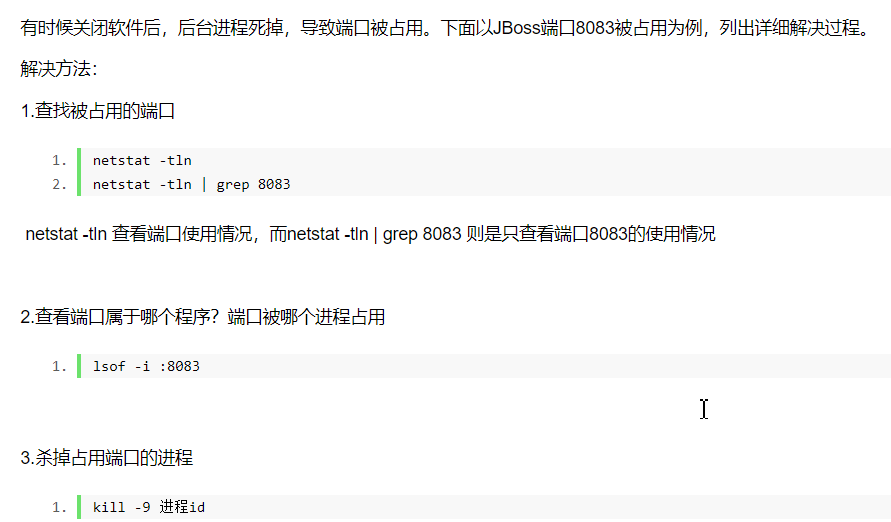
解决linux下端口被占用的问题
不同虚拟机下学习作用
CentOS7
固定IP 192.168.10.11
已创建的用户与密码
用户名 密码
root root
parkour xiaoqinyun1993
学习用的CentOS7, 用于学习
Linux基础命令,Shell脚本编程, Redis, Docker
CentOS7下常用软件的安装
安装vmtools工具
vmtools可以使我们在windows和虚拟机中的linux中复制粘贴文字, 按照上述安装linux默认就已经安装好vmtools了,不用再重新安装了. 如果发现不能相互复制粘贴文字,则按照下述步骤重新安装一下
安装JDK
安装版本: jdk-8u144-linux-x64.tar.gz
安装Tomcat
安装版本:apache-tomcat-7.0.70.tar.gz
安装MySQL
创建了一个用户root 密码root
安装版本: MySQL 5.6.14
概述:通过源代码安装高版本的5.6.14。
正文:
第一步:卸载旧版本
使用下面的命令检查是否安装有MySQL Server
rpm -qa | grep mysql
有的话通过下面的命令来卸载掉
目前我们查询到的是这样的:
[root@hsp ~]# rpm -qa | grep mysql
mysql-libs-5.1.73-7.el6.x86_64
如果查询到了,就删除吧
rpm -e mysql_libs //普通删除模式
rpm -e –nodeps mysql_libs // 强力删除模式,如果使用上面命令删除时,提示有依赖的其它文件,则用该命令可以对其进行强力删除
第二步:安装MySQL
安装编译代码需要的包
yum -y install make gcc-c++ cmake bison-devel ncurses-devel
下载MySQL 5.6.14 【这里我们已经下载好了,看软件文件夹】
tar xvf mysql-5.6.14.tar.gz
cd mysql-5.6.14
编译安装[源码=>编译]
cmake -DCMAKE_INSTALL_PREFIX=/usr/local/mysql -DMYSQL_DATADIR=/usr/local/mysql/data -DSYSCONFDIR=/etc -DWITH_MYISAM_STORAGE_ENGINE=1 -DWITH_INNOBASE_STORAGE_ENGINE=1 -DWITH_MEMORY_STORAGE_ENGINE=1 -DWITH_READLINE=1 -DMYSQL_UNIX_ADDR=/var/lib/mysql/mysql.sock -DMYSQL_TCP_PORT=3306 -DENABLED_LOCAL_INFILE=1 -DWITH_PARTITION_STORAGE_ENGINE=1 -DEXTRA_CHARSETS=all -DDEFAULT_CHARSET=utf8 -DDEFAULT_COLLATION=utf8_general_ci
编译并安装
make && make install
整个过程需要30分钟左右……漫长的等待
第三步:配置MySQL
设置权限
使用下面的命令查看是否有mysql用户及用户组
cat /etc/passwd 查看用户列表
cat /etc/group 查看用户组列表
如果没有就创建
创建一个mysql组
groupadd mysql
创建一个mysql用户并且指定该用户所属的组为mysql
useradd -g mysql mysql
修改/usr/local/mysql权限, R表示递归,将/usr//local/mysql下的所有文件,目录和子目录的权限都赋予mysql组中的mysql用户
chown -R mysql:mysql /usr/local/mysql
删除CentOS7在etc目录下默认生成的/etc/my.cnf文件
初始化配置,进入安装路径(再执行下面的指令)
cd /usr/local/mysql
执行初始化配置脚本,创建系统自带的数据库和表
scripts/mysql_install_db –basedir=/usr/local/mysql –datadir=/usr/local/mysql/data –user=mysql
执行上述命令可能会报错

解决办法: 安装autoconf库(安装此包时会安装Data:Dumper模块)
切换到opt目录下 cd /opt/
执行安装命令yum -y install autoconf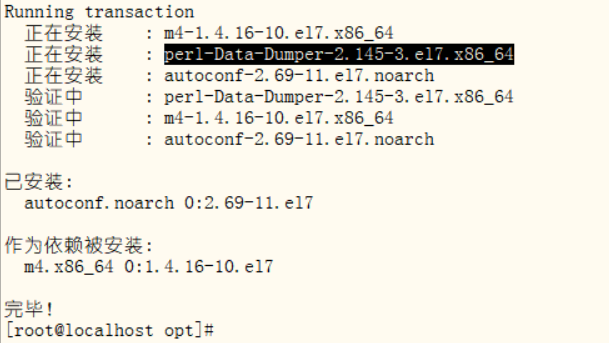
安装完毕之后再切换回mysql目录, 在该目录下执行下面数据初始化脚本,不再报错
cd /usr/local/mysql
scripts/mysql_install_db --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data --user=mysql
注:在启动MySQL服务时,会按照一定次序搜索my.cnf,先在/etc目录下找,找不到则会搜索”$basedir/my.cnf”,在本例中就是 /usr/local/mysql/my.cnf,这是新版MySQL的配置文件的默认位置!
注意:在安装好CentOS7操作系统后,在/etc目录下会自动生成一个my.cnf,需要将此文件删除或更名为其他的名字,如:/etc/my.cnf.bak,否则,该文件会干扰源码安装的MySQL的正确配置,造成无法启动。
修改名称,防止干扰:
mv /etc/my.cnf /etc/my.cnf.bak第四步: 启动MySQL服务
添加服务,拷贝服务脚本到init.d目录,并设置开机启动
[注意在 /usr/local/mysql 下执行]
cp support-files/mysql.server /etc/init.d/mysql
chkconfig mysql on
service mysql start --启动MySQL
执行下面的命令修改root密码
cd /usr/local/mysql/bin
./mysql -uroot
mysql> SET PASSWORD = PASSWORD('root');第五步: 测试MySQL是否安装成功
mysql> show databases;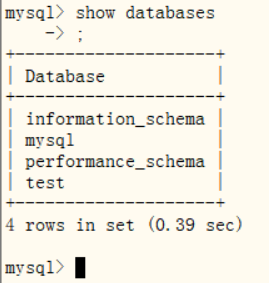
第六步: 将MySQL的bin目录配置到环境变量中
vim /etc/profile
# 在最后配置mysql环境变量后保存退出
MYSQL_HOME=/usr/local/mysql
PATH=/usr/local/mysql/bin:$PATH
export MYSQL_HOME PATH第七步: 注销用户重新登录使环境变量生效
安装Redis
安装Nginx
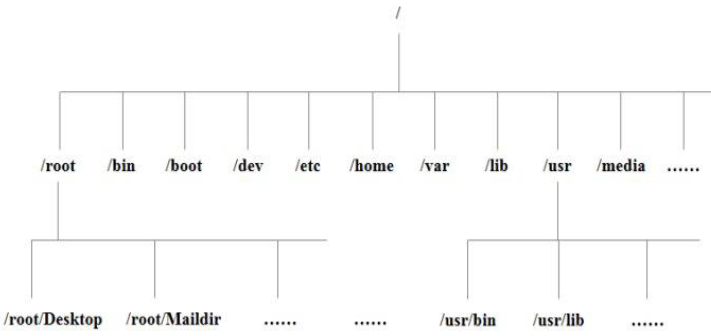
Linux目录结构
CentOS7常见问题与注意事项
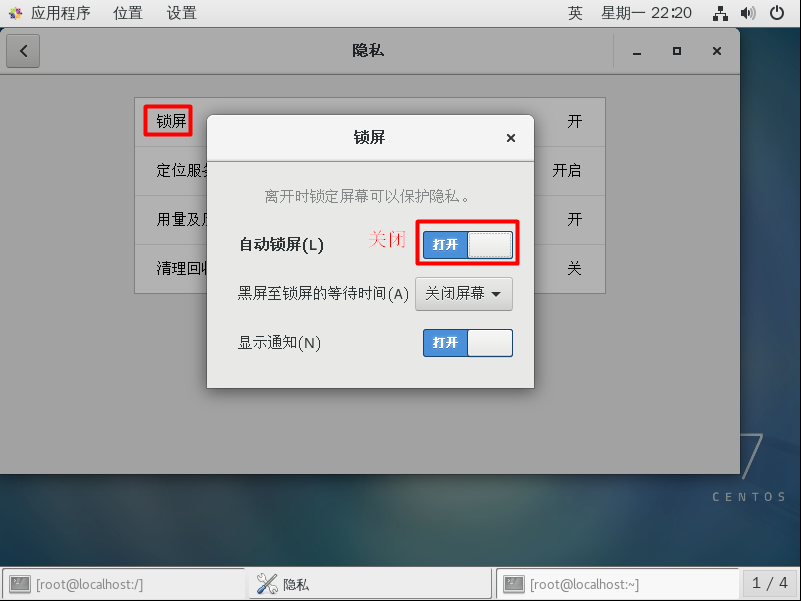
关闭息屏
CentOS7如果一段时间不操作会息屏,按照下面操作关闭息屏
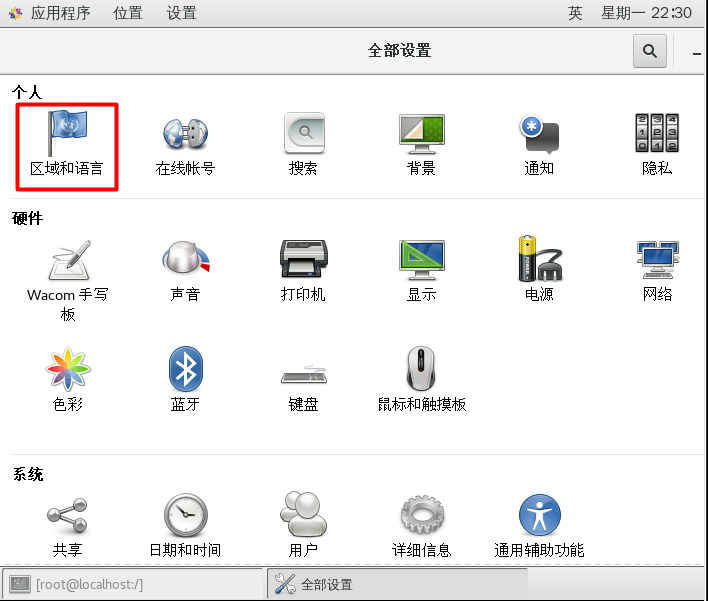
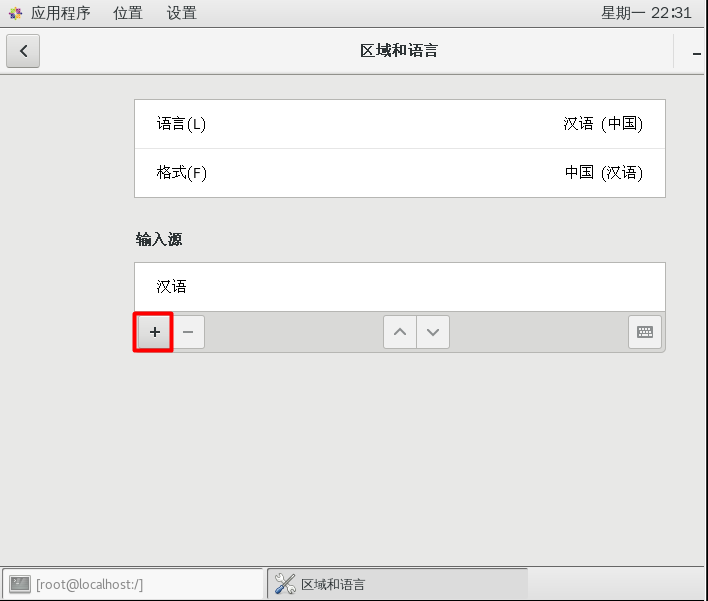
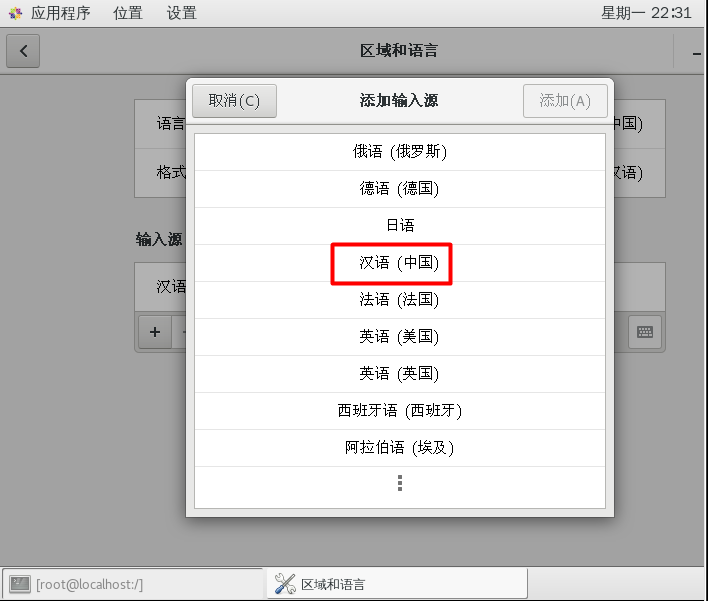
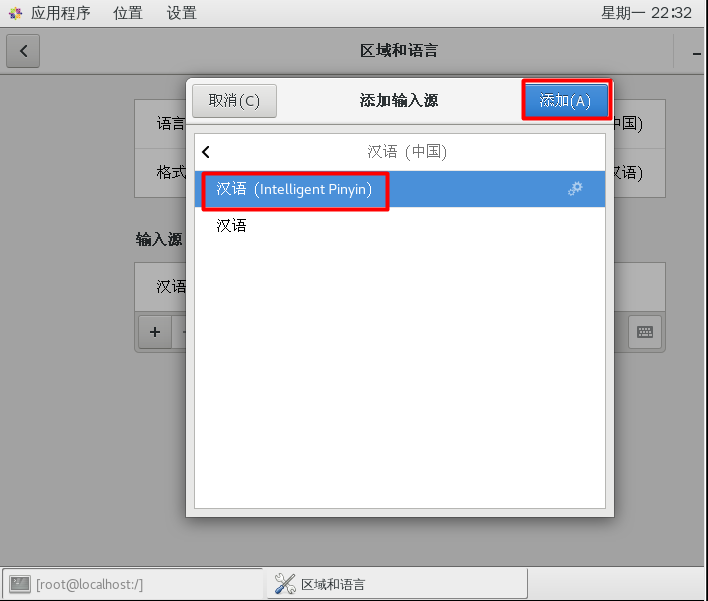
CentOS7添加中文拼音输入法
安装完CentOS7默认是没有中文输入法的,在终端或者火狐浏览器中只能输入英文,要使用中文输入法,进行如下设置 换好之后,中英文切换按shift即可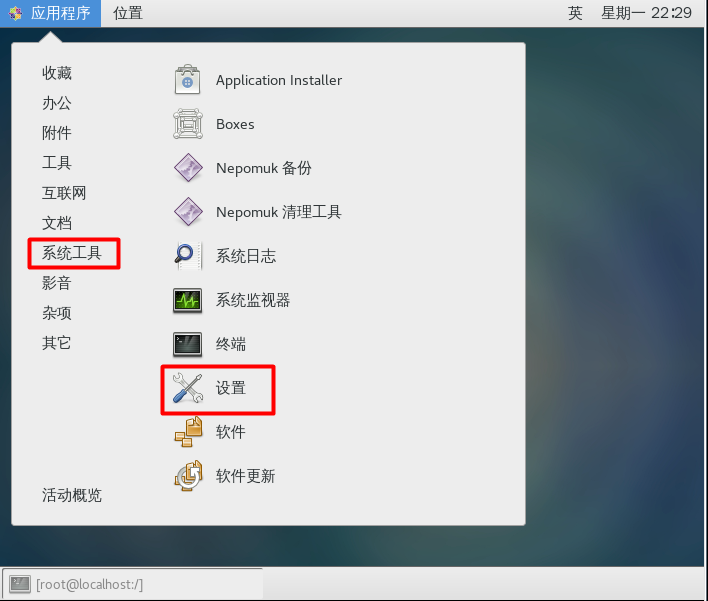

通过CMD将Window本地文件传输到CentOS

然后提示输入登录密码
然后就开始上传了
通过CMD从CentOS下载文件到本地
CentOS传输文件到本地很简单,就是把 scp 命令的两个参数对调一下。
不知道按到哪里将光标变粗了如何恢复
如图所示,不知道按到哪里将光标变粗了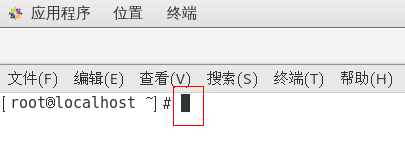
解决办法如下: 依次点击 编辑–>配置文件首选项 将贯标形状修改成 I形即可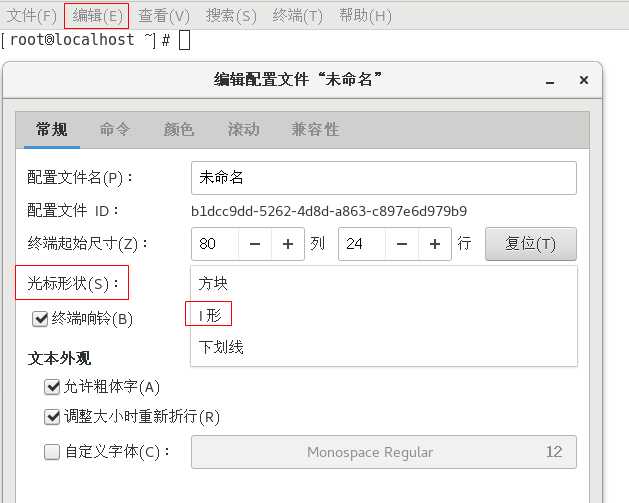
Linux环境下待分类的问题
Linux下部署jar包项目后台运行
nohup java -jar XXX.jar这样部署完成项目之后,程序第一次会在当前jar包所在位置生成一个nohup.out文件,将项目启动日志写入该文件中
如果项目代码中配置了日志输出路径,那么第一个部署成功之后删掉这个文件即可,后期的日志文件就会生成到项目日志框架配置文件制定的路径下
Linux下查看当前启用了的java程序线程
ps aux|grep javaShell编程
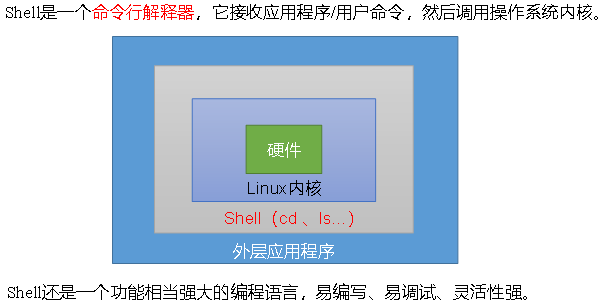
第1章 Shell概述
第2章 Shell解析器
(1)Linux提供的Shell解析器有6种,常用两种(bash和sh):
[root@localhost~]$ cat /etc/shells
/bin/sh
/bin/bash
/sbin/nologin
/bin/dash
/bin/tcsh
/bin/csh(2)bash和sh的关系
(可以看出sh只是bash的一个快捷方式,linux叫做软连接,所以实际上我们只用bash解析器)
[root@localhost bin]$ ll | grep bash
-rwxr-xr-x. 1 root root 941880 5月 11 2016 bash
lrwxrwxrwx. 1 root root 4 5月 27 2017 sh -> bash(3)CentOS默认的解析器是bash
[root@localhost bin]$ echo $SHELL
/bin/bash第3章 Shell脚本入门
1.脚本格式
脚本以#!/bin/bash开头(指定解析器)
2.第一个Shell脚本:helloworld
(1)需求:创建一个Shell脚本,输出helloworld
(2)案例实操:
[root@localhost datas]$ touch helloworld.sh
[root@localhost datas]$ vi helloworld.sh在helloworld.sh中输入如下内容
#!/bin/bash
echo "helloworld"(3)脚本的常用执行方式
第一种:采用bash或sh+脚本的相对路径或绝对路径(不用赋予脚本+x权限)
sh+脚本的相对路径
[root@localhost datas]$ sh helloworld.sh
Helloworldsh+脚本的绝对路径
[root@localhost datas]$ sh /home/parkour/datas/helloworld.sh
helloworldbash+脚本的相对路径
[root@localhost datas]$ bash helloworld.sh
Helloworldbash+脚本的绝对路径
[root@localhost datas]$ bash /home/parkour/datas/helloworld.sh
Helloworld第二种:采用输入脚本的绝对路径或相对路径执行脚本(必须具有可执行权限+x)
(a)首先要赋予helloworld.sh 脚本的+x权限
[root@localhost datas]$ chmod 777 helloworld.sh(b)执行脚本
相对路径(在开发中用的最多的是这种方式)
[root@localhost datas]$ ./helloworld.sh
Helloworld绝对路径
[root@localhost datas]$ /home/parkour/datas/helloworld.sh
Helloworld注意:
第一种执行方法,本质是bash解析器帮你执行脚本,所以脚本本身不需要执行权限。
第二种执行方法,本质是脚本需要自己执行,所以需要执行权限。
3.第二个Shell脚本:多命令处理
(1)需求:
在/home/parkour/目录下创建一个banzhang.txt,在banzhang.txt文件中增加“I love you”。
(2)案例实操:
[root@localhost datas]$ touch batch.sh
[root@localhost datas]$ vi batch.sh在batch.sh中输入如下内容
#!/bin/bash
cd /home/parkour
rm -f banzhang.txt
touch banzhang.txt
echo "I love you" >> banzhang.txt:wq保存退出,执行bash batch.sh回车然后去/home/parkour目录下就能看见这个文件
第4章 Shell中的变量
4.1 系统变量
1. 常用系统变量
- $HOME 当前用户的家目录
- $PWD 当前所在目录
- $SHELL 查看shell默认的解析器是哪个(默认为bash)
- $USER 查看当前用户是哪个
2.案例实操
(1)查看系统变量的值
[root@localhost datas]$ echo $HOME
/root(2)显示当前Shell中所有变量:set 会输出很多, 左边是变量名, 右边是变量的值
使用echo $BASH会输出/bin/bash
使用|grep可以看到环境变量也是配置在这里面, 比如查询环境变量JAVA_HOME的值
[root@localhost datas]$ set
BASH=/bin/bash
BASH_ALIASES=()
BASH_ARGC=()
BASH_ARGV=()
# ....这后面还有很多没有罗列出来4.2 自定义变量
1.基本语法
(1)定义变量:变量=值
(2)撤销变量:unset 变量
(3)声明静态变量:readonly变量,注意:不能unset
2.变量定义规则
(1)变量名称可以由字母、数字和下划线组成,但是不能以数字开头,环境变量的名称建议大写。
(2)等号两侧不能有空格
(3)在bash中,变量默认类型都是字符串类型,无法直接进行数值运算。
(4)变量的值如果有空格,需要使用双引号或单引号括起来。
3.案例实操
(1)定义变量A
[root@localhost datas]$ A=5
[root@localhost datas]$ echo $A
5(2)给变量A重新赋值
[root@localhost datas]$ A=8
[root@localhost datas]$ echo $A
8(3)撤销变量A
[root@localhost datas]$ unset A
[root@localhost datas]$ echo $A(4)声明静态的变量B=2,不能unset
[root@localhost datas]$ readonly B=2
[root@localhost datas]$ echo $B
2
[root@localhost datas]$ B=9
-bash: B: readonly variable(5)在bash中,变量默认类型都是字符串类型,无法直接进行数值运算
[root@localhost ~]$ C=1+2
[root@localhost ~]$ echo $C
1+2(6)变量的值如果有空格,需要使用双引号或单引号括起来
[root@localhost ~]$ D=I love banzhang
-bash: world: command not found
[root@localhost ~]$ D="I love banzhang"
[root@localhost ~]$ echo $A
I love banzhang(7)可把变量提升为全局环境变量,可供其他Shell程序使用
export 变量名
[root@localhost datas]$ vim helloworld.sh
在helloworld.sh文件中增加echo $B
#!/bin/bash
echo "helloworld"
echo $B
[atroot@localhost datas]$ ./helloworld.sh
Helloworld发现并没有打印输出变量B的值。将变量B设置为全局变量
[root@localhost datas]$ export B
[root@localhost datas]$ ./helloworld.sh
helloworld
2全局变量也能撤销, 撤销全局变量B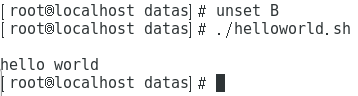
4.3 特殊变量:$n
1.$n基本语法
n为数字,$0代表该脚本名称,$1-$9代表第一到第九个参数,
十以上的参数需要使用大括号包含,如${10}
2.案例实操
(1)输出该脚本文件名称、输入参数1和输入参数2 的值
[root@localhost datas]$ touch parameter.sh
[root@localhost datas]$ vim parameter.sh
#!/bin/bash
echo "$0 $1 $2"
[root@localhost datas]$ chmod 777 parameter.sh
[root@localhost datas]$ ./parameter.sh cls xz
./parameter.sh cls xz4.4 特殊变量:$#
1.$#基本语法
获取所有输入参数个数,常用于循环)。
2.案例实操
(1)获取输入参数的个数
[root@localhost datas]$ vim parameter.sh
#!/bin/bash
echo "$0 $1 $2"
echo $#
[root@localhost datas]$ chmod 777 parameter.sh
[root@localhost datas]$ ./parameter.sh cls xz
parameter.sh cls xz
24.5 特殊变量:$*、$@
1.基本语法
$* (功能描述:这个变量代表命令行中所有的参数,$*把所有的参数看成一个整体)
$@ (功能描述:这个变量也代表命令行中所有的参数,不过$@把每个参数区分对待)
$*和$@的区别见
2.案例实操
(1)打印输入的所有参数
[root@localhost datas]$ vim parameter.sh
#!/bin/bash
echo "$0 $1 $2"
echo $#
echo $*
echo $@
[root@localhost datas]$ bash parameter.sh 1 2 3
parameter.sh 1 2
3
1 2 3
1 2 34.6 特殊变量:$?
1.基本语法
$? (功能描述:最后一次执行命令的返回状态。如果这个变量的值为0,证明上一个命令正确执行;如果这个变量的值为非0(具体是哪个数,由命令自己来决定),则证明上一个命令执行不正确)
2.案例实操
(1)判断helloworld.sh脚本是否正确执行
[root@localhost datas]$ ./helloworld.sh
hello world
[root@localhost datas]$ echo $?
0第5章 运算符
1.基本语法
(1)“$((运算式))”或“$[运算式]”
(2)expr + , - , *, /, % 加,减,乘,除,取余
注意:expr运算符间要有空格
2.案例实操
(1)计算3+2的值
[root@localhost datas]$ expr 2 + 3
5(2)计算3-2的值
[root@localhost datas]$ expr 3 - 2
1(3)计算(2+3)X4的值
(a)expr一步完成计算
[root@localhost datas]$ expr `expr 2 + 3` \* 4
20(b)采用$[运算式]方式(运算符间不需要空格)
(推荐使用这种方式, 因为使用这种方式乘法符号不用写成*)
[root@localhost datas]# S=$[(2+3)*4]
[root@localhost datas]# echo $S
[root@localhost datas]# 20第6章 条件判断
1.基本语法
[ condition ](注意condition前后要有空格)
注意:条件非空即为true,[ atguigu ]返回true,[] 返回false。
2. 常用判断条件
(1)字符串之间比较
= 等于 != 不等于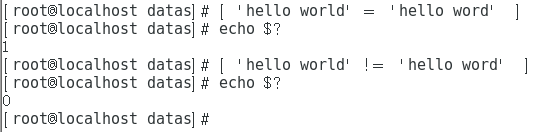
(2)两个整数之间比较
-lt 小于(less than) -le 小于等于(less equal)
-gt 大于(greater than) -ge 大于等于(greater equal)
-eq 等于(equal) -ne 不等于(Not equal)

(3)按照文件权限进行判断
-r 有读的权限(read) -w 有写的权限(write) -x 有执行的权限(execute)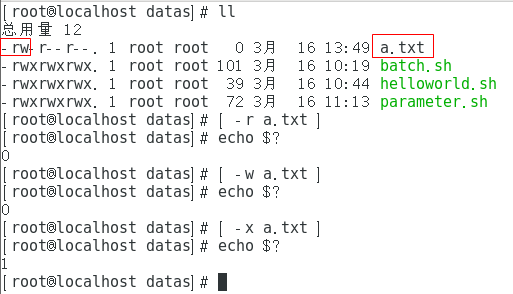
(4)按照文件类型进行判断
-e 文件存在(existence)
-f 文件存在并且是一个常规的文件(file)
-d 文件存在并是一个目录(directory)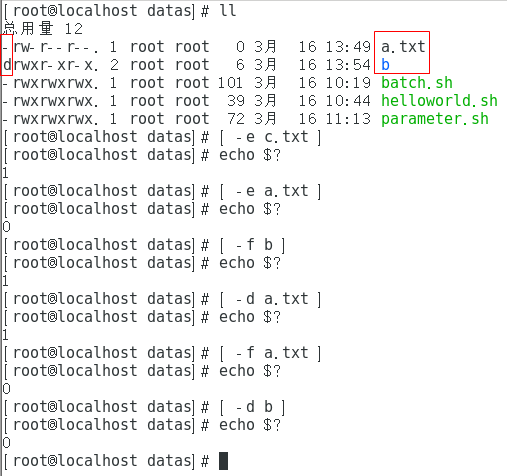
(5)多条件判断
&& 表示前一条命令执行成功时,才执行后一条命令
|| 表示上一条命令执行失败后,才执行下一条命令

第7章 流程控制(重点)
7.1 if 判断
1.基本语法
if [ 条件判断式 ]
then
程序
fi
if [ 条件判断式 ]
then
程序
elif [ 条件判断式 ]
then
程序
fi注意事项:
(1)[ 条件判断式 ],中括号和条件判断式之间必须有空格
(2)if后要有空格
2.案例实操
(1)输入两个数字参数,判断两个数字的大小
7.2 case 语句
1.基本语法
case $变量名 in
"值1")
如果变量的值等于值1,则执行程序1
;;
"值2")
如果变量的值等于值2,则执行程序2
;;
…省略其他分支…
*)
如果变量的值都不是以上的值,则执行此程序
;;
esac注意事项:
- case行尾必须为单词“in”,每一个模式匹配必须以右括号“)”结束。
- 双分号“;;”表示命令序列结束,相当于java中的break。
- 最后的“*)”表示默认模式,相当于java中的default。
2.案例实操
(1)输入一个数字,如果是1,则输出param=1,如果是2,则输出param=2,如果是其它,输出pram=other
7.3 for 循环
1.基本语法1
for (( 初始值;循环控制条件;变量变化 ))
do
程序
done2.案例实操
(1)从1加到100

3.基本语法2
for 变量 in 值1 值2 值3…
do
程序
done4.案例实操
(1)打印所有输入参数
[root@localhost datas]$ touch for2.sh
[root@localhost datas]$ vim for2.sh
#!/bin/bash
#打印数字
for i in $*
do
echo "ban zhang love $i" #注意: 这里只能使用""不能使用''
done
[root@localhost datas]$ chmod 777 for2.sh
[root@localhost datas]$ bash for2.sh cls xz bd
ban zhang love cls
ban zhang love xz
ban zhang love bd(2)比较$*和$@区别
(a)$*和$@都表示传递给函数或脚本的所有参数,不被双引号“”包含时,都以$1 $2 …$n的形式输出所有参数。
[root@localhost datas]$ touch for.sh
[root@localhost datas]$ vim for.sh
#!/bin/bash
for i in $*
do
echo "ban zhang love $i "
done
for j in $@
do
echo "ban zhang love $j"
done
[root@localhost datas]$ bash for.sh cls xz bd
ban zhang love cls
ban zhang love xz
ban zhang love bd
ban zhang love cls
ban zhang love xz
ban zhang love bd(b)当它们被双引号“”包含时,“$*”会将所有的参数作为一个整体,以“$1 $2 …$n”的形式输出所有参数;“$@”会将各个参数分开,以“$1” “$2”…”$n”的形式输出所有参数。
[root@localhost datas]$ vim for.sh
#!/bin/bash
for i in "$*"
#$*中的所有参数看成是一个整体,所以这个for循环只会循环一次
do
echo "ban zhang love $i"
done
for j in "$@"
#$@中的每个参数都看成是独立的,所以“$@”中有几个参数,就会循环几次
do
echo "ban zhang love $j"
done
[root@localhost datas]$ chmod 777 for.sh
[root@localhost datas]$ bash for.sh cls xz bd
ban zhang love cls xz bd
ban zhang love cls
ban zhang love xz
ban zhang love bd7.4 while 循环
1.基本语法
while [ 条件判断式 ]
do
程序
done2.案例实操
(1)从1加到100
[root@localhost datas]$ touch while.sh
[root@localhost datas]$ vim while.sh
#!/bin/bash
s=0
i=1
while [ $i -le 100 ]
do
s=$[$s+$i]
i=$[$i+1]
done
echo $s
[root@localhost datas]$ chmod 777 while.sh
[root@localhost datas]$ ./while.sh
5050第8章 read读取控制台输入
1.基本语法
read(选项)(参数)
选项:
-p:指定读取值时的提示符;
-t:指定读取值时等待的时间(秒)。
参数
变量:指定读取值的变量名
2.案例实操
(1)提示7秒内,读取控制台输入的名称
[root@localhost datas]$ touch read.sh
[root@localhost datas]$ vim read.sh
#!/bin/bash
read -t 7 -p "Enter your name in 7 seconds:" NAME
echo $NAME
[root@localhost datas]$ ./read.sh
Enter your name in 7 seconds:xiaoze
xiaoze第9章 函数
9.1 系统函数
1.basename基本语法
basename [string / pathname] [suffix]
功能描述:basename命令会删掉所有的前缀包括最后一个(‘/’)字符,然后将字符串显示出来。常用来获取文件名
选项:
suffix为后缀,如果suffix被指定了,basename会将pathname或string中的suffix去掉。
案例实操
(1)截取该/home/parkour/banzhang.txt路径的文件名称
[root@localhost datas]$ basename /home/parkour/banzhang.txt
banzhang.txt
[root@localhost datas]$ basename /home/parkour/banzhang.txt .txt
banzhang该命令对文件夹也有效(可以看出在linux系统中一切皆文件,目录也是文件)
2.dirname基本语法
dirname 文件绝对路径
功能描述:从给定的包含绝对路径的文件名中去除文件名(非目录的部分),然后返回剩下的路径(目录的部分)
案例实操
获取banzhang.txt文件的路径(获取banzhang.txt该文件在哪个目录下)
[root@localhost ~]$ dirname /home/atguigu/banzhang.txt
/home/atguigu该命令对文件夹也有效(可以看出在linux系统中一切皆文件,目录也是文件)
9.2 自定义函数
1.基本语法
[ function ] funname[()]
{
该函数要完成的操作
[return int;]
}
funname2.注意事项
(1)必须在调用函数地方之前,先声明函数,shell脚本是逐行运行。不会像其它语言一样先编译。
(2)函数返回值,只能通过$变量名获得,可以显示加:return返回,如果不加,将以最后一条命令运行结果,作为返回值。return后跟数值n(0-255)
3.案例实操
(1)计算两个输入参数的和
[root@localhost datas]$ touch fun.sh
[root@localhost datas]$ vim fun.sh
#!/bin/bash
function sum()
{
s=0
s=$[ $1 + $2 ]
echo $s
}
read -p "Please input the number1: " n1;
read -p "Please input the number2: " n2;
sum $n1 $n2;
[root@localhost datas]$ chmod 777 fun.sh
[root@localhost datas]$ ./fun.sh
Please input the number1: 2
Please input the number2: 5
7第10章 Shell工具(重点)
10.1 cut
cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段输出。
1.基本用法
cut [选项参数] filename
说明:默认分隔符是制表符
2.选项参数说明
-f 列号,提取第几列
-d 分隔符,按照指定分隔符分割列
3.案例实操
(0)数据准备
[root@localhost datas]$ touch cut.txt
[root@localhost datas]$ vim cut.txt
dong shen
guan zhen
wo wo
lai lai
le le(1)切割cut.txt第一列
[root@localhost datas]$ cut -d " " -f 1 cut.txt
dong
guan
wo
lai
le(2)切割cut.txt第二、三列
[root@localhost datas]$ cut -d " " -f 2,3 cut.txt
shen
zhen
wo
lai
le(3)在cut.txt文件中切割出guan
[root@localhost datas]$ cat cut.txt | grep "guan" | cut -d " " -f 1
guan(4)选取系统PATH变量值,使用:进行分割, 提取分割后第2个元素到最后一个元素的值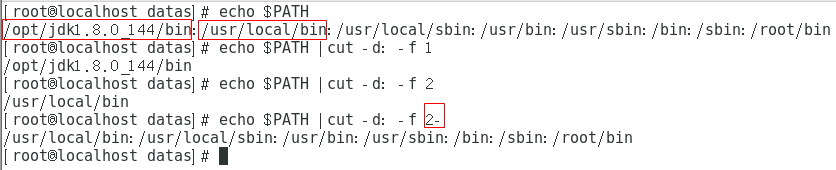
10.2 sed
sed是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”,接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。
1.基本用法
sed [选项参数] ‘command’ filename
2.选项参数说明
-e 直接在指令列模式上进行sed的动作编辑。
3.命令功能描述
| 命令 | 功能描述 |
|---|---|
| a | 新增,a的后面可以接字串,在下一行出现 |
| d | 删除 |
| s | 查找并替换 |
4.案例实操
(0)数据准备
[root@localhost datas]$ touch sed.txt
[root@localhost datas]$ vim sed.txt
dong shen
guan zhen
wo wo
lai lai
le le(1)将“mei nv”这个单词插入到sed.txt第二行后新的一行,打印。
[root@localhost datas]$ sed "2a mei nv" sed.txt
dong shen
guan zhen
mei nv
wo wo
lai lai
le le
[root@localhost datas]$ cat sed.txt
dong shen
guan zhen
wo wo
lai lai
le le注意:并没有改变文件原来的内容
(2)删除sed.txt文件所有包含wo的行
[root@localhost datas]$ sed "/wo/d" sed.txt
dong shen
guan zhen
lai lai
le le注意:并没有改变文件原来的内容
(3)将sed.txt文件中wo替换为ni
[root@localhost datas]$ sed "s/wo/ni/g" sed.txt
dong shen
guan zhen
ni ni
lai lai
le le注意:‘g’表示全局替换
注意:并没有改变文件原来的内容
(4)将sed.txt文件中的第二行删除并将wo替换为ni
[root@localhost datas]$ sed -e "2d" -e "s/wo/ni/g" sed.txt
dong shen
ni ni
lai lai
le le10.3 gawk
一个强大的文本分析工具,把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行分析处理。
1.基本用法
gawk [选项参数] 'pattern1{action1} pattern2{action2}...' filename
pattern:表示gawk在数据中查找的内容,就是匹配模式
action:在找到匹配内容时所执行的一系列命令
2.选项参数说明
-F 指定输入文件折分隔符
-v 赋值一个用户定义变量
3.案例实操
(0)数据准备
[root@localhost datas]$ sudo cp /etc/passwd ./(1)搜索passwd文件以root关键字开头的所有行,并输出该行的第7列。
[root@localhost datas]$ gawk -F: '/^root/{print $7}' passwd
/bin/bash(2)搜索passwd文件以root关键字开头的所有行,并输出该行的第1列和第7列,中间以“,”号分割。
[root@localhost datas]$ gawk -F: '/^root/{print $1","$7}' passwd
root,/bin/bash注意:只有匹配了pattern的行才会执行action
(3)只显示/etc/passwd的第一列和第七列,以逗号分割,且在所有行前面添加列名user,shell在最后一行添加”dahaige,/bin/zuishuai”。
[root@localhost datas]$ gawk -F : 'BEGIN{print "user, shell"} {print $1","$7} END{print "dahaige,/bin/zuishuai"}' passwd
user, shell
root,/bin/bash
bin,/sbin/nologin
......此处省略n行
atguigu,/bin/bash
dahaige,/bin/zuishuai注意:BEGIN 在所有数据读取行之前执行;END 在所有数据执行之后执行。
(4)将passwd文件中的用户id增加数值1并输出
[root@localhost datas]$ gawk -v i=1 -F: '{print $3+i}' passwd
1
2
3
4
......此处省略n行4.gawk的内置变量
| 变量 | 说明 |
|---|---|
| FILENAME | 文件名 |
| NR | 已读的记录数 |
| NF | 浏览记录的域的个数(切割后,列的个数) |
5.案例实操
(1)统计passwd文件的 文件名, 使用:号切割后 每行的行号,每行的列数
[root@localhost datas]$ gawk -F: '{print "filename:" FILENAME ", linenumber:" NR ",columns:" NF}' passwd
filename:passwd, linenumber:1,columns:7
filename:passwd, linenumber:2,columns:7
filename:passwd, linenumber:3,columns:7
......此处省略n行(2)切割IP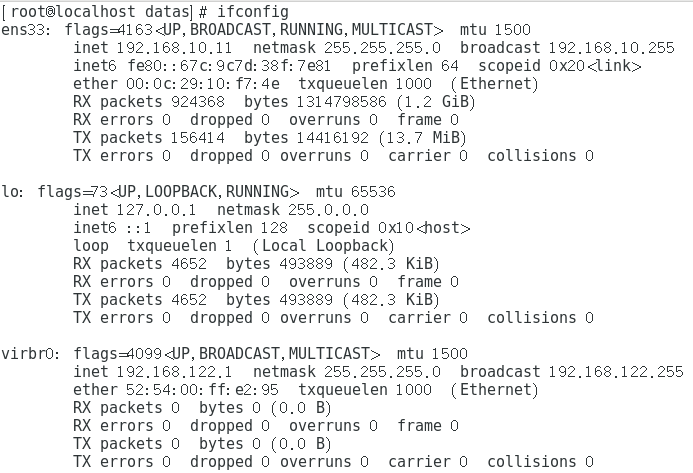
[root@localhost datas]# ifconfig ens33 | grep "inet " | gawk -F " " '{print $2}'
192.168.10.11
[root@localhost datas]# (3)查询sed.txt中空行所在的行号
[root@localhost datas]$ gawk '/^$/{print NR}' sed.txt
510.4 sort
sort将文件进行排序,并将排序结果标准输出。
1.基本语法
sort(选项)(参数)
| 选项 | 说明 |
|---|---|
| -t | 设置排序时所用的分隔字符 |
| -n | 依照数值的大小排序 |
| -r | 以相反的顺序来排序 |
| -k | 指定需要排序的列 |
参数:指定待排序的文件列表
2.案例实操
(1)数据准备
[root@localhost datas]$ touch sort.sh
[root@localhost datas]$ vim sort.sh
bb:40:5.4
bd:20:4.2
xz:50:2.3
cls:10:3.5
ss:30:1.6(2)按照”:”分割后的第三列倒序排序。
[root@localhost datas]$ sort -t : -nrk 3 sort.sh
bb:40:5.4
bd:20:4.2
cls:10:3.5
xz:50:2.3
ss:30:1.6(3)查询datas目录下第一级子目录所有文件和文件夹,并按照文件大小由大到小的顺序排序(逆序)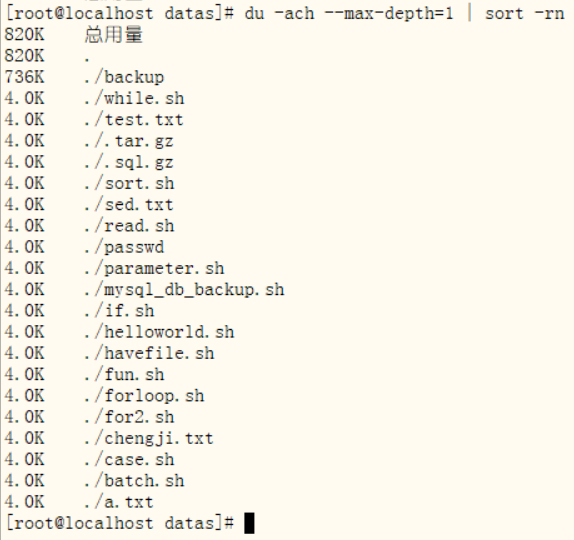
第11章 企业真实面试题(重点)
11.1 京东
问题1:使用Linux命令查询file1中空行所在的行号
答案:
[root@localhost datas]$ gawk '/^$/{print NR}' sed.txt
5问题2:有文件chengji.txt内容如下:
zhangsan 40
lisi 50
wangwu 60使用Linux命令计算第二列的和并输出
[root@localhost datas]$ cat chengji.txt | gawk -F " " '{sum+=$2} END{print sum}'
15011.2 搜狐&和讯网
问题1:Shell脚本里如何检查一个文件是否存在?如果不存在该如何处理?
#!/bin/bash
if [ -f file.txt ]
then
echo "文件存在!"
else
echo "文件不存在!"
fi11.3 新浪
问题1:用shell写一个脚本,对文本中无序的一列数字排序,并求出所有数据的和
[root@CentOS6-2 ~]# cat test.txt
9
8
7
6
5
4
3
2
10
1
[root@CentOS6-2 ~]# sort -n test.txt|gawk '{a+=$0;print $0}END{print "SUM="a}'
1
2
3
4
5
6
7
8
9
10
SUM=5511.4 金和网络
问题1:请用shell脚本写出查找当前文件夹(./)下所有的文本文件内容中包含有字符”shen”的文件名称
[root@localhost datas]# grep -r "shen" ./ | cut -d ":" -f 1
./sed.txt
[root@localhost datas]#11.5 编写Shell脚本定时备份数据库
需求:
1)每天凌晨2:10 备份数据库mysql到/datas/backup/db
2)备份开始和备份结束能够给出相应的提示信息
3)备份后的文件要求以备份时间为文件名,并打包成.tar.gz 的形式,比如:2018-03-12_230201.tar.gz

- 在备份的同时,检查是否有10天前备份的数据库文件,如果有就将其删除。
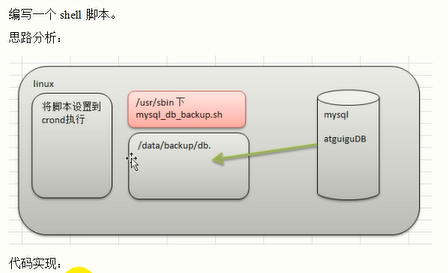
mysql_db_backup.sh脚本文件内容如下
#!/bin/bash
#完成数据库的定时备份
#备份的路径
BACKUP=/datas/backup/db
#使用当前的时间作为文件名
DATETIME=$(date +%Y_%m_%d_%H%M%S)
#输出变量调式
echo $DATETIME
echo '=====开始备份====='
echo '=====备份的路径是 $BACKUP/$DATETIME.tar.gz'
#主机
HOST=localhost
#用户名
DB_USER=root
#密码
DB_PWD=root
#备份数据库名
DATABASE=mysql
#创建备份的路径
#如果备份的路径存在就使用,否则就创建
[ ! -d "$BACKUP/$DATETIME" ] && mkdir -p "$BACKUP/$DATETIME"
#执行mysqldump备份数据库,备份后的生成$DATETIME.sql文件
mysqldump -u${DB_USER} -p${DB_PWD} --default-character-set=gbk --host=$HOST $DATABASE | gzip > $BACKUP/$DATETIME/$DATETIME.sql.gz
#对备份后的文件夹进行打包
cd $BACKUP
tar -zcvf $DATETIME.tar.gz $DATETIME
#删除临时目录
rm -rf $BACKUP/$DATETIME
#删除10天前的备份文件
find $BACKUP -mtime +10 -name "*.tar.gz" -exec rm -rf {} \;
echo "============备份数据库成功==============="测试脚本是否可以备份
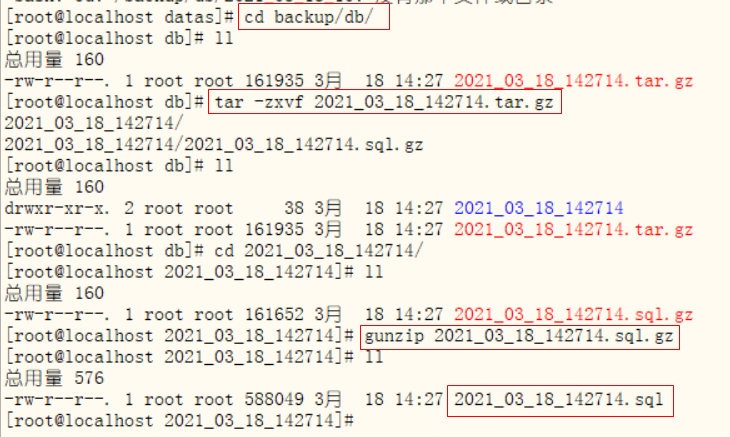
可以看到备份数据库成功
创建定时任务,执行该脚本文件
编写定时任务,wq保存退出即可
正则表达式语法
| 字符 | 说明 |
|---|---|
| \ | 将下一字符标记为特殊字符、文本、反向引用或八进制转义符。例如,”n”匹配字符”n”。”\n”匹配换行符。序列”\\“匹配”",”\(“匹配”(“。 |
| ^ | 匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与”\n”或”\r”之后的位置匹配。 |
| $ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与”\n”或”\r”之前的位置匹配。 |
| * | 零次或多次匹配前面的字符或子表达式。例如,zo* 匹配”z”和”zoo”。* 等效于 {0,}。 |
| + | 一次或多次匹配前面的字符或子表达式。例如,”zo+”与”zo”和”zoo”匹配,但与”z”不匹配。+ 等效于 {1,}。 |
| ? | 零次或一次匹配前面的字符或子表达式。例如,”do(es)?”匹配”do”或”does”中的”do”。? 等效于 {0,1}。 |
| {n} | n 是非负整数。正好匹配 n 次。例如,”o{2}”与”Bob”中的”o”不匹配,但与”food”中的两个”o”匹配。 |
| {n,} | n 是非负整数。至少匹配 n 次。例如,”o{2,}”不匹配”Bob”中的”o”,而匹配”foooood”中的所有 o。”o{1,}”等效于”o+”。”o{0,}”等效于”o*”。 |
| {n,m} | M 和 n 是非负整数,其中 n <= m。匹配至少 n 次,至多 m 次。例如,”o{1,3}”匹配”fooooood”中的头三个 o。’o{0,1}’ 等效于 ‘o?’。注意:您不能将空格插入逗号和数字之间。 |
| ? | 当此字符紧随任何其他限定符(*、+、?、{n}、{n,}、{n,m})之后时,匹配模式是”非贪心的”。”非贪心的”模式匹配搜索到的、尽可能短的字符串,而默认的”贪心的”模式匹配搜索到的、尽可能长的字符串。例如,在字符串”oooo”中,”o+?”只匹配单个”o”,而”o+”匹配所有”o”。 |
| . | 匹配除”\r\n”之外的任何单个字符。若要匹配包括”\r\n”在内的任意字符,请使用诸如”[\s\S]”之类的模式。 |
| (pattern) | 匹配 pattern 并捕获该匹配的子表达式。可以使用 $0…$9 属性从结果”匹配”集合中检索捕获的匹配。若要匹配括号字符 ( ),请使用”(“或者”)“。 |
| [xyz] | 字符集。匹配包含的任一字符。例如,”[abc]”匹配”plain”中的”a”。 |
| [^xyz] | 反向字符集。匹配未包含的任何字符。例如,”[^abc]”匹配”plain”中”p”,”l”,”i”,”n”。 |
| [a-z] | 字符范围。匹配指定范围内的任何字符。例如,”[a-z]”匹配”a”到”z”范围内的任何小写字母。 |
| [^a-z] | 反向范围字符。匹配不在指定的范围内的任何字符。例如,”[^a-z]”匹配任何不在”a”到”z”范围内的任何字符。 |
| \b | 匹配一个字边界,即字与空格间的位置。例如,”er\b”匹配”never”中的”er”,但不匹配”verb”中的”er”。 |
| \B | 非字边界匹配。”er\B”匹配”verb”中的”er”,但不匹配”never”中的”er”。 |
| \cx | 匹配 x 指示的控制字符。例如,\cM 匹配 Control-M 或回车符。x 的值必须在 A-Z 或 a-z 之间。如果不是这样,则假定 c 就是”c”字符本身。 |
| \d | 数字字符匹配。等效于 [0-9]。 |
| \D | 非数字字符匹配。等效于 [^0-9]。 |
| \f | 换页符匹配。等效于 \x0c 和 \cL。 |
| \n | 换行符匹配。等效于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等效于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等。与 [ \f\n\r\t\v] 等效。 |
| \S | 匹配任何非空白字符。与 [^ \f\n\r\t\v] 等效。 |
| \t | 制表符匹配。与 \x09 和 \cI 等效。 |
| \v | 垂直制表符匹配。与 \x0b 和 \cK 等效。 |
| \w | 匹配任何字类字符,包括下划线。与”[A-Za-z0-9_]”等效。 |
| \W | 与任何非单词字符匹配。与”[^A-Za-z0-9_]”等效。 |
| \xn | 匹配 n,此处的 n 是一个十六进制转义码。十六进制转义码必须正好是两位数长。例如,”\x41”匹配”A”。”\x041”与”\x04”&”1”等效。允许在正则表达式中使用 ASCII 代码。 |
| \num | 匹配 num,此处的 num 是一个正整数。到捕获匹配的反向引用。例如,”(.)\1”匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义码或反向引用。如果 \n 前面至少有 n 个捕获子表达式,那么 n 是反向引用。否则,如果 n 是八进制数 (0-7),那么 n 是八进制转义码。 |
| \nm | 标识一个八进制转义码或反向引用。如果 \nm 前面至少有 nm 个捕获子表达式,那么 nm 是反向引用。如果 \nm前面至少有 n 个捕获,则 n 是反向引用,后面跟有字符 m。如果两种前面的情况都不存在,则 \nm 匹配八进制值 nm,其中 n 和 m 是八进制数字 (0-7)。 |
| \nml | 当 n 是八进制数 (0-3),m 和 l 是八进制数 (0-7) 时,匹配八进制转义码 nml。 |
| \un | 匹配 n,其中 n 是以四位十六进制数表示的 Unicode 字符。例如,\u00A9 匹配版权符号 (©)。 |
x|y 匹配 x 或 y。例如,’z|food’ 匹配”z”或”food”。’(z|f)ood’ 匹配”zood”或”food”。
(?:pattern) 匹配 pattern 但不捕获该匹配的子表达式,即它是一个非捕获匹配,不存储供以后使用的匹配。这对于用”or”字符 (|) 组合模式部件的情况很有用。例如,’industr(?:y|ies) 是比 ‘industry|industries’ 更经济的表达式。
(?=pattern) 执行正向预测先行搜索的子表达式,该表达式匹配处于匹配 pattern 的字符串的起始点的字符串。它是一个非捕获匹配,即不能捕获供以后使用的匹配。例如,’Windows (?=95|98|NT|2000)’ 匹配”Windows 2000”中的”Windows”,但不匹配”Windows 3.1”中的”Windows”。预测先行不占用字符,即发生匹配后,下一匹配的搜索紧随上一匹配之后,而不是在组成预测先行的字符后。
(?!pattern) 执行反向预测先行搜索的子表达式,该表达式匹配不处于匹配 pattern 的字符串的起始点的搜索字符串。它是一个非捕获匹配,即不能捕获供以后使用的匹配。例如,’Windows (?!95|98|NT|2000)’ 匹配”Windows 3.1”中的 “Windows”,但不匹配”Windows 2000”中的”Windows”。预测先行不占用字符,即发生匹配后,下一匹配的搜索紧随上一匹配之后,而不是在组成预测先行的字符后。
第20章 其他待分类
20.1 放到linux上的jar包运行报错, jar包中的某个依赖包被压缩了
报错:
Caused by: java.lang.IllegalStateException: Unable to open nested entry 'BOOT-INF/lib/ojdbc7-12.1.0.2.0.jar'. It has been compressed and nested jar files must be stored without compression. Please check the mechanism used to create your executable jar file原因:
替换或者导入jar包时,jar包被自动压缩,springboot规定嵌套的jar包不能在被压缩的情况下存储。
解决(本文以升级ojdbc包为例):
使用jar命令解压jar包,在压缩包外重新替换jar包,在进行压缩。
步骤1:解压jar包
PS D:\ttmp> jar -xvf *.jar
已创建: META-INF/
已解压: META-INF/MANIFEST.MF
已创建: BOOT-INF/
已创建: BOOT-INF/classes/
已创建: BOOT-INF/classes/com/步骤2:替换jar包
rm -f BOOT-INF/lib/ojdbc14-10.2.0.4.0.jar 先将原来被压缩的jar包删除
mv ojdbc7-12.1.0.2.0.jar BOOT-INF/lib/ 然后将未压缩的jar包放入原来的lib目录下步骤3:重新压缩jar
jar -cfM0 new.jar BOOT-INF/ META-INF/ org/tee命令
tee命令用于读取标准输入的数据,并将其内容输出成文件。
tee指令会从标准输入设备读取数据,将其内容输出到标准输出设备,同时保存成文件。
语法:
tee [-ai][--help][--version][文件...]参数:
- -a或–append 附加到既有文件的后面,而非覆盖它.
- -i或–ignore-interrupts 忽略中断信号。
- –help 在线帮助。
- –version 显示版本信息。
实例:
如果想同时打印到屏幕和文件里,可以这么写:
$ ls -l | tee -a lsls.logLinux环境下安装nodejs
第1步: 下载与安装
首先去官网下载对应的版本
所有可获得的版本列表, Ctrl+F 搜索要安装的版本
然后复制对应版本号的链接, 比如我要下载 v12.18.1 版本的, 直接复制对应的链接,使用 wget命令下载
首先先切换到 /opt目录 (因为Linux里面opt目录用来存放软件安装包)
cd /opt然后执行wget命令下载对应的软件包 (注意: 要下载 linux-x64.tar.xz 结尾的文件)
wget https://nodejs.org/dist/v12.18.1/node-v12.18.1-linux-x64.tar.xz然后安装xz (xz结尾的文件解压需要使用xz)
yum install xz -y然后使用xz将 node-v12.18.1-linux-x64.tar.xz 解压成 node-v12.18.1-linux-x64.tar压缩文件
xz -dk node-v12.18.1-linux-x64.tar.xz然后再使用tar执行解压操作
tar -xf node-v12.18.1-linux-x64.tar解压完成之后,将解压后的目录剪切放到 /usr/local/node目录下 (因为Linux里面/usr/local/目录用来存放对应的软件)
mv /opt/node-v12.18.1-linux-x64 /usr/local/cd进入 /usr/local/node-v12.18.1-linux-x64/bin 查看一下目录结构
cd /usr/local/node-v12.18.1-linux-x64/bin
ll在该目录下依次执行 node -v 和 npm -v 都会报命令找不到的错误
第2步: 配置环境变量
修改linux系统的环境变量(profile)来设置直接运行命令
先备份,养成修改重要文件之前先备份的好习惯
cp /etc/profile /etc/profile.bak修改环境变量
vim /etc/profile在最下面添加 export PATH=$PATH: 后面跟上node下bin目录的路径
按 i 进入编辑状态,按 ctrl+c 退出编辑,再 :wq 保存退出
export NODE_HOME=/usr/local/node-v12.18.1-linux-x64
export PATH=$PATH:$NODE_HOME/bin使修改后的环境配置立即生效
source /etc/profile查看node和npm版本号(如果命令找不到,则重新打开命令行窗口)
node -v
npm -vLinux补充命令
1. 查看操作系统是多少位的
getconf LONG_BIT2. 查看某个端口是否被哪个进程占用
# 查看6379端口有没有被占用
lsof -i:6379


