Oracle的安装
安装版本: oracle 10g 因为这个版本是企业用的最多的
先安装服务端 10201_database_win32
- 选中setup.exe鼠标右键点击兼容性勾选以兼容模式运行这个程序后点击确定
- 以管理员身份运行setup.exe进行安装
- 指定oracle安装的主目录,安装类型选择企业版,全局数据库名默认orcl 数据库口令orcl,点击下一步
- 在产品特定的先决条件检查页面勾选所有的检查项,然后点击下一步,出现概要页面点击安装即可
- 出现Database Configuration Assistant界面后点击口令管理,打开口令管理界面
- 找到scott用户取消勾选”是否锁定账户?”,为该用户设置口令密码tiger,点击确定
- oracle比较耗内存,在计算机服务中只需要开启OracleServiceORCL和OracleOraDb10g_home1TNSListener即可,所以设置这两个服务手动开启,禁用其他Oracle开头的服务
再安装客户端 10201_client_win32
- 选中setup.exe鼠标右键点击兼容性勾选以兼容模式运行这个程序后点击确定
- 以管理员身份运行setup.exe进行安装
- 欢迎使用界面点击下一步,选择安装类型界面,选择管理员,点击下一步
- 指定主目录详细信息界面 选择客户端的安装目录,点击下一步
- 在产品特定的先决条件检查页面勾选所有的检查项,然后点击下一步,出现概要页面点击安装即可
- 出现 oracle net configuration assistant: 欢迎使用界面 点击下一步,再点击下一步 出现服务名配置界面 填写服务名orcl,下一步,选择TCP,下一步
- 设置主机名127.0.0.1(或localhost),使用标准端口号1521,下一步,点击测试连接数据库,如果连接不成功,点击更改登录,输入用户名和密码(比如sys,orcl或system,orcl或scott,tiger(注意:使用pl/sql developer登录的时候, 必须使用管理员权限打开pl/sql软件才行))
- 测试连接成功之后, 一路点击下一步,最后点击完成,安装成功点击退出即可
使用Navicat连接Oracle数据库
创建一个新的oracle连接,新建查询后输入一句查询语句select sysdate from dual;
查询到当前时间说明连接操作数据库成功
注:可以在“企业用户管理器”进行用户的添加、删除、具体用户的权限设置等操作
导入学习oracle的SQL脚本文件, 以scott用户名和tiger密码登录oracle,新建查询
D:\Java\JavaPractice\oracle\del_date.sql
D:\Java\JavaPractice\oracle\hr_cre.sql
D:\Java\JavaPractice\oracle\hr_popul.sql
@d:/del_date.sql; #SQL文件所在地址
@d:/hr_cre.sql; #SQL文件所在地址
@d:/hr_popul.sql; #SQL文件所在地址查看是否导入SQL成功,执行下面命令查询employees表中的数据
select * from employees;
-- 查询结果: 107rows selected
```
**引入的三个表之间的表结构**

# Oracle的卸载
1. 开始->设置->控制面板->管理工具->服务停止所有Oracle服务;
2. 开始->程序->Oracle – OraDb10g_home1>Oracle Installation Products-> Universal Installer 卸装所有Oracle产品,但Universal Installer本身不能被删除;
3. 运行regedit,选择HKEY_LOCAL_MACHINE\SOFTWARE\ORACLE,按del键删除这个入口;
4. 运行regedit,选择HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services,滚动这个列表,删除所有Oracle入口;
5. 运行refedit,选择HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Eventlog\Application,删除所有Oracle入口;
6. 开始->设置->控制面板->系统->高级->环境变量,删除环境变量CLASSPATH和PATH中有关Oracle的设定;
7. 从桌面上、STARTUP(启动)组、程序菜单中,删除所有有关Oracle的组和图标;
8. 删除c:\Program Files\Oracle目录;
9. 重新启动计算机,重起后才能完全删除Oracle所在目录 ;
10. 删除与Oracle有关的文件,选择Oracle所在的缺省目录C:\Oracle,删除这个入口目录及所有子目录,并从Windows XP目录(一般为d:\WINDOWS)下删除以下文件ORACLE.INI、oradim73.INI、oradim80.INI、oraodbc.ini等等;
11. WIN.INI文件中若有`[ORACLE]`的标记段,删除该段;
12. 如有必要,删除所有Oracle相关的ODBC的DSN;
13. 到事件查看器中,删除Oracle相关的日志 说明:如果有个别DLL文件无法删除的情况,则不用理会,重新启动,开始新的安装,o安装时,选择一个新的目录,则,安装完毕并重新启动后,原来的目录及文件就可以删除掉了。
# Oracle其他细节知识
oracle证书: OCA OCP OCM
oracle数据库: 一个相关的操作系统文件(即存储在计算机硬盘升的文件)集合,这些文件 组织在一起,成为一个逻辑整体,即oracle数据库
oracle实例: 用来管理和访问oracle数据库的服务
区别: 一个实例只能与一个数据库关联,访问一个数据库
而同一个数据库可以同时被多个实例访问
word中SQL语句单引号格式赋值过去需要修改,不然会报错
PL/SQL developer软件: ed打开编辑框,在编辑框中的SQL语句最后不加;号,保存后输入/并回车 执行SQL语句
desc 表: 查看表结构
dual伪表
sysdate 系统时间
SQL语句的分类
* DDL:数据定义语言create / drop / alter
* DML:数据操作语句insert / delete /update / truncate
* DQL:数据查询语言select / show
* DCL:数据控制语言grant/ revoke
Oracle默认端口1521
# 管理表
**查看表的结构**
```sql
-- desc 表名
desc employees显示employees表各个字段的详细信息查询数据
不带条件的查询
查询所有字段
select * from 表名 SELECT * FROM employees;查询指定字段
select 字段1,字段2 from 表名 SELECT employee_id,last_name FROM employees;基本SQL-SELECT语句
空值: 空值不是空格或者0
SELECT last_name, job_id, salary, commission_pct FROM employees;包含空值的数学表达式的值都为空值
SELECT last_name, 12*salary*commission_pct FROM employees;别名, 包含空格和需要原样输出的别名可以使用双引号
SELECT last_name AS name, commission_pct comm FROM employees;
SELECT last_name "Name", salary*12 "Annual Salary" FROM employees;连接符||
select ‘hello’||’ world’ from dual;日期和字符必须使用单引号引起来, 默认的日期格式是 dd-M月-yyyy
select ‘1993-12-09’ from dual;
select ‘parkour’ from dual;删除重复行distinct
select distinct department_id from employees;批量插入数据的两种方法
insert into 表1 (select 要插入的字段 from 表2);使用truncate和delete删除的区别
使用delete可以通过where删除满足指定条件的记录,并且支持事务回滚rollback
delete from emps where id = '100';
rollback 回滚
commit 确认要删除之后记得提交事务使用truncate会将整个表的记录全部删除, 并且不支持事务回滚rollback
truncate table emps;所以要删除一个表的所有记录,使用truncate会比使用delete快很多
rollback和commit
记住所有insert/update/delete操作,最后都需要手动commit提交事务才能生效
rollback不仅允许回滚整个未提交的事务,还允许回滚事务的一部分,这可以通过“保存点”来完成。在事务的执行过程中,用户可以通过建立保存点将一个较长的失误分隔为几部分。这样用户就可以有选择性地回滚到某个保存点,并且该保存点之后的操作都将被取消。
例: 像emps表中插入先后插入两条记录,然后使用保存点(savepoint)来回滚最后添加的那条记录
select * from emps; 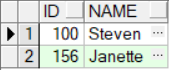
truncate table emps;
select * from emps; 
insert into emps values(1,’zhangsan’);
savepoint sp; -- 设置保存点insert into emps values(2,’lisi’);
select * from emps; 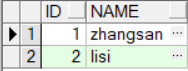
rollback to savepoint sp;
commit; -- 回滚到保存点并提交事务select * from emps;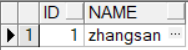
过滤和排序数据
使用where将不符合条件的结果过滤掉
select last_name,department_id from employees
where department_id=20;在两值之间between…and…(包含边界,闭区间)
select last_name,department_id from employees
where department_id between 10 and 30;*between…and…还可以与not关键字一起使用*
-- 例如: 查询工资不在3000至5000范围内的员工
select * from employees where salary not between 3000 and 5000;所有值列表中的一个in
select last_name,department_id from employees
where department_id in(10,20,30);in还可以有与not关键字一起使用
-- 例如: 查询部门ID不属于(30,60,90)号部门的员工
select * from employees where department_id not in(30,60,90);模糊查询like
/*
_ 匹配一个字符
% 匹配任意个字符
\_ escape ’\’ 转义_
*/
select last_name from employees where last_name like’_a%’;
select last_name from employees where last_name like’%a%’;
select last_name from employees where last_name like ‘%\_a%’ escape ’\’;[ ]:表示括号内所列字符中的一个(类似正则表达式)。指定一个字符、字符串或范围,要求所匹配对象为它们中的任一个。
例如 SELECT * FROM test WHERE name LIKE ‘[陈李王]三’
将找出“陈三”、“李三”、“王三”的所有记录;
如果 [ ] 内有一系列字符(如:01234、abcde等等)则可略写为“0-4”、“a-e”
SELECT * FROM test WHERE name LIKE ‘陈[1-9]‘
则表示“陈1”、“陈2”、……、“陈9”;
[^ ] :表示不在括号所列之内的单个字符。其取值和 [] 相同,但它要求所匹配对象为指定字符以外的任一个字符。
比如 SELECT * FROM test WHERE name LIKE ‘[^陈李王]三’
将找出不是‘陈三’,‘李三’,‘王三’的所有记录,可以是‘张三’,‘赵三’等。
SELECT * FROM test WHERE name LIKE ‘陈[^1-4]‘;
将排除“陈1”到“陈4”,寻找“陈5”、“陈6”、……的所有记录。
like还可以与not关键字一起使用
-- 例如: 查询员工姓名中不包含字母d的员工
select * from employees where last_name not like '%d%';is null 和 is not null 判断是否为空
select last_name,commission_pct from employee where commission_pct is null;
select last_name,commission_pct from employee where commission_pct is not null;排序 order by desc 降序 order by asc 升序(缺省asc也是按照升序)
select last_name,salary from employees order by salary desc;
select last_name,salary from employees order by salary asc;也可以按照别名进行排序
select last_name,salary “工资” from employees order by “工资” asc;指定多个排序列(当按照一个列进行排序后又相同的数据,再按照另外一个列排序)
select last_name,salary from employees order by salary desc,department_id desc;单行函数
单行函数(返回一个结果)
字符函数
lower(‘PARKOUR’) parkour
upper(‘parkour’) PARKOUR
initcap(‘parkour hello’) Parkour Hello
concat (‘hello’,’ world’) hello world
substr(‘helloworld’,1,3) hel
substr(‘helloworld’,3) lloworld
length(‘hello’) 5 如果参数为null 则返回null
instr(‘hello’,’l’) 3 匹配第一次出现的位置,索引从1开始,没有匹配到返回0
lpad(‘hello’,10,’*’) 左对齐 *****hello
rpad(‘hello’,10,’*’) 右对齐 hello*****
trim(’r’ from ‘rparkour’) parkou (不要忘了写from)
trim(‘ parkour ’) parkour 若只有一个参数,则去除左右空格
replace(‘rparkour’,’r’,’h’) hpahkouh
replace(‘rparkour’,’r’) pakou1、instr()函数的格式 (俗称:字符查找函数)
格式一:instr( string1, string2 ) / instr(源字符串, 目标字符串)
instr(v_zh_claim_stutas_pro,’c’)>0
//v_zh_claim_stutas_pro→string1,’c’→string2
格式二:instr( string1, string2 [, start_position [, nth_appearance ] ] ) / instr(源字符串, 目标字符串, 起始位置, 匹配序号)
解析:string2 的值要在string1中查找,是从start_position给出的数值(即:位置)开始在string1检索,检索第nth_appearance(几)次出现string2。
select instr('helloworld','l',2,2) from dual; --返回结果:4 也就是说:在"helloworld"的第2(e)号位置开始,查找第二次出现的“l”的位置
select instr('helloworld','l',3,2) from dual; --返回结果:4 也就是说:在"helloworld"的第3(l)号位置开始,查找第二次出现的“l”的位置
select instr('helloworld','l',4,2) from dual; --返回结果:9 也就是说:在"helloworld"的第4(l)号位置开始,查找第二次出现的“l”的位置
select instr('helloworld','l',-1,1) from dual; --返回结果:9 也就是说:在"helloworld"的倒数第1(d)号位置开始,往回查找第一次出现的“l”的位置
select instr('helloworld','l',-2,2) from dual; --返回结果:4 也就是说:在"helloworld"的倒数第1(d)号位置开始,往回查找第二次出现的“l”的位置
select instr('helloworld','l',2,3) from dual; --返回结果:9 也就是说:在"helloworld"的第2(e)号位置开始,查找第三次出现的“l”的位置
select instr('helloworld','l',-2,3) from dual; --返回结果:3 也就是说:在"helloworld"的倒数第2(l)号位置开始,往回查找第三次出现的“l”通用函数
适用返回: 适用于任何数据类型,同时也适用于空值:
NVL (expr1, expr2) 如果expr1不为空,则直接返回expr1,如果expr1为空则返回expr2
NVL2 (expr1, expr2, expr3) 如果expr1不为空,则返回expr2,如果expr1为空则返回expr3
NULLIF (expr1, expr2) 如果expr1和expr2相等,返回null,不相等返回expr1
COALESCE (expr1, expr2, …, exprn) 从左往右数,遇到第一个非null值,则返回该非null值
select coalesce(0,1,2) from dual;
/*返回结果
0
*/
select coalesce(null,1,2) from dual;
/*返回结果
1
*/
select coalesce(null,null,2) from dual;
/*返回结果
2
*/
select coalesce(null,null,null) from dual;
/*返回结果
/*
```
### 日期函数
**date 将一个日期类型的字符串转换成date类型**
```sql
select date '2019-11-30' from dual;在日期上加上或减去一个数字结果仍为日期,两个日期相减返回日期之间相差的天数,日期不允许做加法运算
SELECT last_name, (SYSDATE-hire_date)/7 AS WEEKS
FROM employees
WHERE department_id = 90;months_between两个日期相差的月数
select months_between(date '2019-12-06', date '1993-12-06') from dual;add_months(d,i)返回日期d 加上i 个月之后的结果
select add_months(sysdate,2) from dual;next_day指定日期的下一个星期 * 对应的日期
2019-11-30这天是星期六
2019-11-30这个日期对应的下一个星期2的日期为2019-12-03
注意: 西方每个星期的第一天是从星期天开始计算的,所以这里需要2+1
select next_day(date '2019-11-30',3) from dual;
```


**last_day(date)返回和当前时分秒相同某月的最后一天的日期**
```sql
select sysdate,LAST_DAY(sysdate-31),LAST_DAY(sysdate+2) from dual;
select last_day('9-12月-1993') from dual;round日期的四舍五入
select round(sysdate,’year’) from dual; --舍入到最接近的年
/*
查询结果
2019/1/1
*/select round(sysdate,’month’) from dual; --舍入到最接近的月,系统时间为2019/5/21
/*
查询结果
2019/6/1
*/select round(sysdate,’day’) from dual;
-- 舍入到最接近的星期日,系统时间为 2019/5/21
-- 上一个星期日2019/5/19,离2019/5/21有2天
-- 下一个星期日为2019/5/26离2019/5/21有5天
/*
查询结果
2019/5/19
*/trunc日期截断
select sysdate from dual --返回当前系统时间 带时分秒
--返回结果 2019/12/14 23:22:14
select trunc(sysdate) from dual --返回当前日期 无时分秒
--返回结果 2019/12/14
select trunc(sysdate, 'mm') from dual --返回当月第一天
--返回结果 2019/12/1
select trunc(sysdate,'yy') from dual --返回当年第一天
--返回结果 2019/1/1
select trunc(sysdate,'d') from dual --返回当前星期的第一天,外国人一个星期的第一天是从星期日开始算起的,每个星期的最后一天是星期六
--返回结果 2019/12/8转换函数
隐式数据类型转换
Oracle 自动完成下列转换
date<---->char或varchar2<---->number显式数据类型转换
char或varchar2转date使用to_date()函数
select to_date('1993-12-09','yyyy-mm-dd') from dual;
SELECT TO_CHAR(sysdate,‘yyyy-mm-dd hh:mi:ss’) FROM dual;使用to_date可能会报错: ORA-01849: 小时值必须介于 1 和 12 之间
ORACLE数据库查询语句:
select * from dual where time>=to_date('2012-10-29 19:45:34','yyyy-mm-dd HH:mi:ss');
```
当执行时,会抛出错误:
ORA-01849: 小时值必须介于 1 和 12 之间 01849. 00000 - "hour must be between 1 and 12"
这是因为,在ORACLE中,时间格式默认小时为12小时制,如果想运行以上语句,应该将时间格式改成为'yyyy-mm-dd HH24:mi:ss'即可
**date转char或varchar2使用to_char()函数**
```sql
select to_char(sysdate,'yyyy"年"mm"月"dd"日"') from dual;
```
**char或varchar2转number使用to_number()函数**
```sql
select to_number('123') from dual;number转char或varchar2使用to_char()函数
select to_char(123456789,'999,999,999') from dual;
/*返回结果
123,456,789
*/
select to_char(123456789,’$999,999,999’) from dual;
/*返回结果
$123,456,789
*/
select to_char(123456789,’L999,999,999’) from dual;
/*返回结果
¥123,456,789
*/
select to_char(1234567,’000,999,999’) from dual;
/*返回结果
001,234,567
*/下面是在TO_CHAR 函数中经常使用的几种格式:
9 数字
0 零
$ 美元符号
L 本地货币符号
. 小数点
, 千位符
数值函数
round四舍五入 round(3.45) 3.45 round(3.45,1) 3.5
trunc截断 trunc(3.1415) 3 trunc(3.1415,2) 3.14
mod求余 mod(10,3) 1
abs绝对值 abs(-1) 1
ceil(n) 返回大于或等于数值n的最小整数
ceil(7.3) 8 ceil(7) 7 ceil(-7.3) -7florr(n) 返回小于或等于n 的最大整数
florr (7.3) 7 florr (7) 7 florr (-7.3) -8power(n1,n2) 返回n1的n2次方
sign(n)判断一个数的正负, 如果n为正数返回1 负数返回-1 0返回0 null返回null
sqrt(n) 如果n>=0返回n的平方根,如果n为负数报错, 如果n为null 返回null
多行函数
多行函数(返回多个结果)
其他函数
wm_concat功能是:实现行转列功能,即将查询出的某一列值使用逗号进行隔开拼接,成为一条数据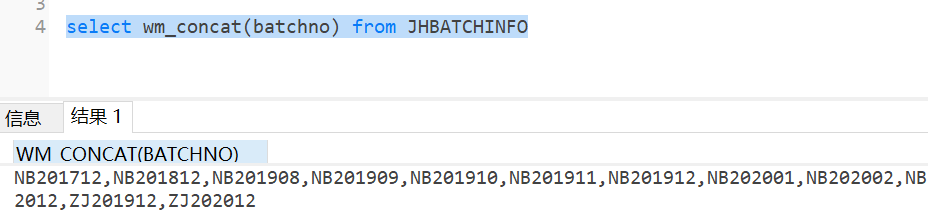
withas: 创建临时表
with查询语句不是以select开始的,而是以“WITH”关键字开头.可认为在真正进行查询之前预先构造了一个临时表,之后便可多次使用它做进一步的分析和处理
语法: with 临时表名 as(查询语句) select * from 临时表名
创建一个别名
with temp as (select * from 表1)
select * from temp
```
创建多个别名
```sql
with
temp1 as (select * from 表1),
temp2 as (select * from 表2),
temp3 as (select * from 表3),
select * from tempX条件表达式
case
case when then else end的2种写法
case A when B then C else D end
case when A then B else D endCASE expr WHEN comparison_expr1 THEN return_expr1
[WHEN comparison_expr2 THEN return_expr2
WHEN comparison_exprn THEN return_exprn
ELSE else_expr]
ENDselect last_name,salary,department_id,case department_id when 10 then salary*10
when 20 then salary*20
when 30 then salary*30
else salary as department_sal
end
from employees;decode
DECODE(col|expression, search1, result1 ,
[, search2, result2,...,]
[, default])select last_name,department_id,salary,
decode(department_id,10,1.1*salary,
20,1.2*salary,
30,1.3*salary,
salary) department_sal
from employees order by department_id多表查询
SQL语句的多表查询方式
例如:按照department_id查询employees(员工表)和departments(部门表)的信息。
方式一(通用型):SELECT … FROM … WHERE
SELECT e.last_name,e.department_id,d.department_name
FROM employees e,departments d
where e.department_id = d.department_id;方式二:SELECT … FROM … NATURAL JOIN …
有局限性:会自动连接两个表中相同的列(可能有多个:department_id和manager_id)
SELECT last_name,department_id,department_name
FROM employees
NATURAL JOIN departments;方式三:SELECT … JOIN … USING …
有局限性:好于方式二,但若多表的连接列列名不同,此法不合适
SELECT last_name,department_id,department_name
FROM employees
JOIN departments
USING(department_id);方式四:SELECT … FROM … JOIN … ON …
常用方式,较方式一,更易实现外联接(左、右、满)
SELECT last_name,e.department_id,department_name
FROM employees e
JOIN departments d
ON e.department_id = d.department_id;使用连接在多个表中查询数据,在 WHERE 子句中写入连接条件。在表中有相同列时,在列名之前加上表名前缀
select last_name,department_name from employees e,departments d where e.department_id=d.department_id;连接n个表,至少需要 n-1个连接条件
练习:查询出公司员工的 last_name, department_name, city
select last_name,department_name,city from employees e,departments d,locations l
where e.department_id=d.department_id and d.location_id=l.location_id;非等值连接
列名数据不是一一对应的,有一列的数据可能多余另一列的数据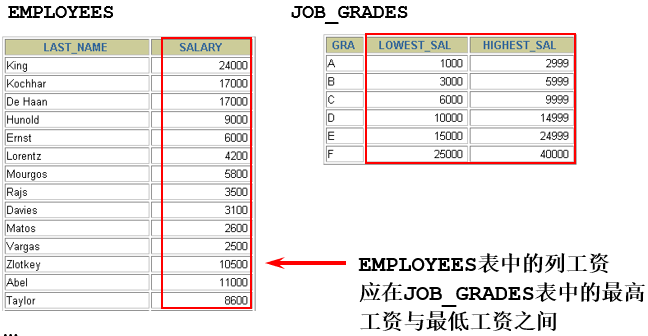
练习: 查询员工姓名,工资和工资所对应级别
select last_name,salary,grade_level from employees e,job_grades j
where e.salary between j.lowest_sal and j.highest_sal;内连接
内连接: 合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行. 内连接只返回满足连接条件的数据
等值连接
不等值连接
自连接
非自连接
外连接
外连接: 两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件的行 ,这种连接称为左(或右) 外连接.没有匹配的行时, 结果表中相应的列为空(NULL). 外连接的 WHERE 子句条件类似于内部连接, 但连接条件中没有匹配行的表的列后面要加外连接运算符, 即用圆括号括起来的加号(+).
使用外连接可以查询不满足连接条件的数据。外连接的符号是 (+)
练习: 查询员工姓名,员工所在部门编号,部门名
select e.last_name,e.department_id,d.department_name
from employees e,departments d
where e.department_id(+)=d.department_id;
```
自连接
自连接: 即在一张表中进行查询
练习1:查询出所有员工姓名和对应老板ID和对应老板姓名
```sql
select e.last_name employee_name,e.manager_id boss_id,m.last_name boss_name from employees e,employees m
where e.manager_id=m.employee_id;
```
练习2: 查询employees表,返回“Xxx works for Xxx”
```sql
select worker.last_name || ’ works for ’ || manager.last_name
from employees worker,employees manager
where worker.manager_id=manager.employee_id;
```
### 左连接left join(用的多)
```sql
select e.last_name,e.department_id,d.department_name
from employees e
left join departments d
on e.department_id=d.department_id;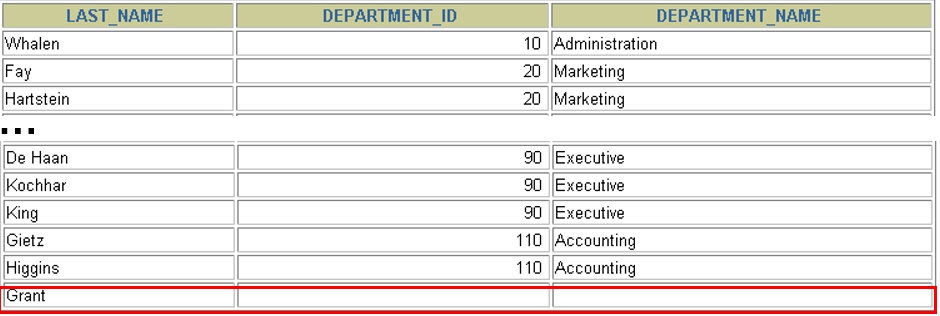
右连接right join(和左连接原理相同,但一般习惯用左连接)
select e.last_name,e.department_id,d.department_name
from employees e
right join departments d
on e.department_id=d.department_id;
满连接(用的少)
两个表在连接过程中除了返回满足连接条件的行以外还返回两个表中不满足条件的行 ,这种连接称为满外连接。
select e.last_name,e.department_id,d.department_name
from employees e
full join departments d
on e.department_id=d.department_id;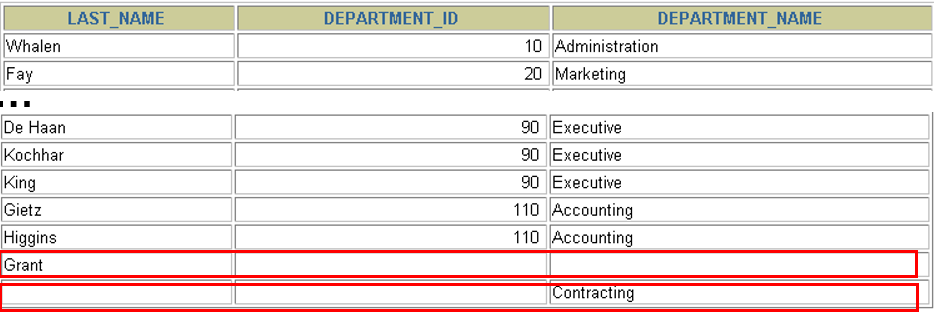
自然连接(用的很少)
NATURAL JOIN 子句,会以两个表中具有相同名字的列为条件创建等值连接。
在表中查询满足等值条件的数据。如果只是列名相同而数据类型不同,则会产生错误。
返回的是,两个表中具有相同名字的列的“交集”即:比如employees表和departments表都有department_id列和manager_id列,使用natural join会以该列为条件创建等值连接
select last_name,department_name
from employees natural join departments;
/*
一共返回32条结果
32 rows selected
这里为什么不是106条呢?
原因在于取的是department_id和manager_id都匹配的交集
*/
```
使用join+using(指定匹配列) 查询
```sql
select last_name,department_name
from employees
join departments using(department_id);
/*
一共返回106条结果
106 rows selected
*/使用on子句创建连接
自然连接中是以具有相同名字的列为连接条件的。可以使用 ON 子句指定额外的连接条件。
这个连接条件是与其它条件分开的。ON 子句使语句具有更高的易读性。
select e.employee_id,e.last_name,e.department_id,d.location_id
from employees e join departments d
on e.department_id=d.department_id;
```
使用 ON 子句创建多表连接
```sql
select employee_id,department_name,city
from employees e
join departments d
on e.department_id=d.department_id
join locations l
on d.location_id=l.location_id;
```
# 分组函数
分组函数作用于一组数据,并对一组数据返回一个值。

**常见组函数**
**avg count max min sum stddev标准方差**
```sql
select avg(salary),count(employee_id),max(salary),min(salary),stddev(salary),sum(salary)
from employees;组函数统计结果会忽略空值
select count(commission_pct) from employees; -- 统计有奖金的员工有几个NVL函数使分组函数无法忽略空值
select count(nvl(commission_pct, 0)),count(commission_pct) from employees;
/*
根据员工的奖金率,统计员工的个数
返回结果
*/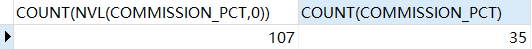
第一列返回所有员工的个数 , 第二列返回有奖金的员工人数
组函数结合distinct关键字
COUNT(DISTINCT expr)返回expr非空且不重复的记录总数
select count(distinct department_id) from employees;
-- 返回所有有部门的员工的部门数使用group by关键字进行分组
GROUP BY 子句可以基于指定某一列的值将数据集合划分为多个分组,同一组内所有记录在分组属性上具有相同值,也可以基于指定多列的值将数据集合划分为多个分组。
练习: 求出employees表中各个部门的平均工资
select department_id,avg(salary) from employees group by department_id;
```
在SELECT 列表中所有未包含在组函数中的列都应该包含
在 GROUP BY 子句中
### 使用多个列进行分组
在GROUP BY子句中包含多个列
查询每个department_id下对应的job_id和,每个job_id下的总工资salary,
并按照department_id进行分组查询,如何department_id相同则再按照job_id分组查询
```sql
select department_id,job_id,sum(salary)
from employees
group by department_id,job_id;
```
#### 非法使用组函数的情况
(1)所有包含于SELECT 列表中而未包含于组函数中的列都必须包含于GROUP BY 子句中。

(2)不能在 WHERE 子句中使用组函数。可以在 HAVING 子句中使用组函数。

使用having进行过滤分组
HAVING 子句对GROUP BY 子句选择出来的结果进行再次筛选,最后输出符合HAVING 子句中条件的记录。HAVING 子句的语法与WHERE 子句的语法“相类似”,唯一不同的是HAVING 子句中可以包含聚合函数,比如常用的聚合函数count、avg、sum 等。 having子句后面还可以跟其他条件比如and or order by等等
练习: 查询部门最高工资大于 10000 的部门ID
```sql
select department_id,max(salary)
from employees
group by department_id
having max(salary)>10000;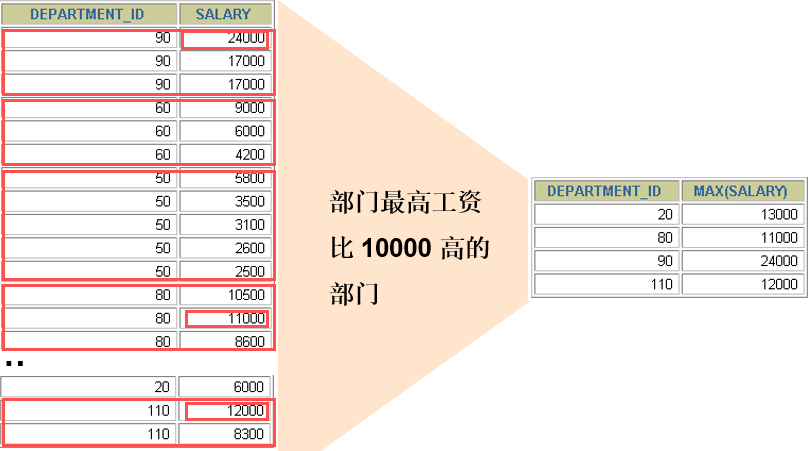
嵌套组函数
显示各个本部门平均工资的最大值
select max(avg(salary)) from employees group by department_id;分组排序函数ROW_NUMBER() OVER()
语法格式:ROW_NUMBER() OVER(partition by 分区字段 order by 排序字段 desc|asc)
row_number() over()分组排序功能:
在使用 row_number() over()函数时候,over()里头的分组以及排序的执行晚于 where 、group by、 order by 的执行。
例一:
表数据:
create table TEST_ROW_NUMBER_OVER(
id varchar(10) not null,
name varchar(10) null,
age varchar(10) null,
salary int null
);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(1,'a',10,8000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(1,'a2',11,6500);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(2,'b',12,13000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(2,'b2',13,4500);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(3,'c',14,3000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(3,'c2',15,20000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(4,'d',16,30000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(5,'d2',17,1800);
```
一次排序:对查询结果进行排序(无分组)
```sql
select id,name,age,salary,row_number()over(order by salary desc) rn
from TEST_ROW_NUMBER_OVER t
```
结果:

进一步排序:根据id分组排序
```sql
select id,name,age,salary,row_number()over(partition by id order by salary desc) rank
from TEST_ROW_NUMBER_OVER t
```
结果:

再一次排序:找出每一组中序号为一的数据
```sql
select * from(select id,name,age,salary,row_number()over(partition by id order by salary desc) rank
from TEST_ROW_NUMBER_OVER t)
where rank <2
```
结果:

排序找出年龄在13岁到16岁数据,按salary排序
```sql
select id,name,age,salary,row_number()over(order by salary desc) rank
from TEST_ROW_NUMBER_OVER t where age between '13' and '16'
```
结果:结果中 rank 的序号,其实就表明了 over(order by salary desc) 是在where age between and 后执行的

例二:
1.使用row_number()函数进行编号,如
```sql
select email,customerID, ROW_NUMBER() over(order by psd) as rows from QT_Customer
```
原理:先按psd进行排序,排序完后,给每条数据进行编号。
2.在订单中按价格的升序进行排序,并给每条记录进行排序代码如下:
```sql
select DID,customerID,totalPrice,ROW_NUMBER() over(order by totalPrice) as rows from OP_Order
```
3.统计出每一个各户的所有订单并按每一个客户下的订单的金额 升序排序,同时给每一个客户的订单进行编号。这样就知道每个客户下几单了:
```sql
select ROW_NUMBER() over(partition by customerID order by totalPrice)
as rows,customerID,totalPrice, DID from OP_Order
```
4.统计每一个客户最近下的订单是第几次下的订单:
```sql
with tabs as
(
select ROW_NUMBER() over(partition by customerID order by totalPrice)
as rows,customerID,totalPrice, DID from OP_Order
)
select MAX(rows) as '下单次数',customerID from tabs
group by customerID
```
5.统计每一个客户所有的订单中购买的金额最小,而且并统计改订单中,客户是第几次购买的:
思路:利用临时表来执行这一操作。
1. 先按客户进行分组,然后按客户的下单的时间进行排序,并进行编号。
2. 然后利用子查询查找出每一个客户购买时的最小价格。
3. 根据查找出每一个客户的最小价格来查找相应的记录。
```sql
with tabs as
(
select ROW_NUMBER() over(partition by customerID order by insDT)
as rows,customerID,totalPrice, DID from OP_Order
)
select * from tabs
where totalPrice in
(
select MIN(totalPrice)from tabs group by customerID
)
```
**6.筛选出客户第一次下的订单**
思路:利用rows=1来查询客户第一次下的订单记录。
```sql
with tabs as
(
select ROW_NUMBER() over(partition by customerID order by insDT) as rows,* from OP_Order
)
select * from tabs where rows = 1
select * from OP_Order7.注意:在使用over等开窗函数时,over里头的分组及排序的执行晚于“where,group by,order by”的执行
select
ROW_NUMBER() over(partition by customerID order by insDT) as rows,
customerID,totalPrice, DID
from OP_Order where insDT>'2011-07-22'ROW_NUMBER()函数
ROW_NUMBER()函数作用就是将select查询到的数据进行排序,每一条数据加一个序号,他不能用做于学生成绩的排名,一般多用于分页查询,
比如查询前10个 查询10-100个学生。
实例:
1.1对学生成绩排序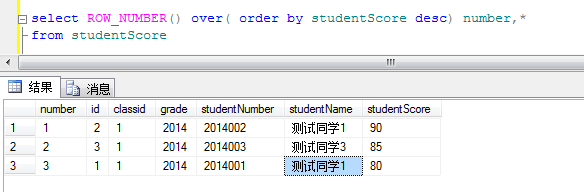
这里number就是每个学生的序号 根据studentScore(分数)进行desc倒序
1.2获取第二个同学的成绩信息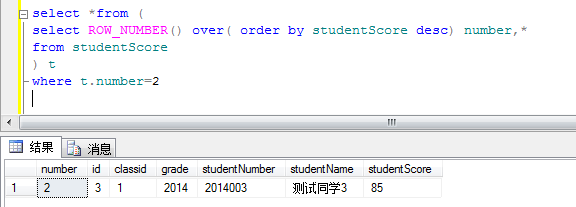
这里用到的思想就是 分页查询的思想 在原sql外再套一层select
where t.number>=1 and t.number<=10 是不是就是获取前十个学生的成绩信息纳。
跳跃排名函数RANK()
定义:RANK()函数,顾名思义排名函数,可以对某一个字段进行排名,这里为什么和ROW_NUMBER()不一样那,ROW_NUMBER()是排序,当存在相同成绩的学生时,ROW_NUMBER()会依次进行排序,他们序号不相同,而Rank()则不一样出现相同的,他们的排名是一样的。下面看例子:
2.1对学生成绩进行排名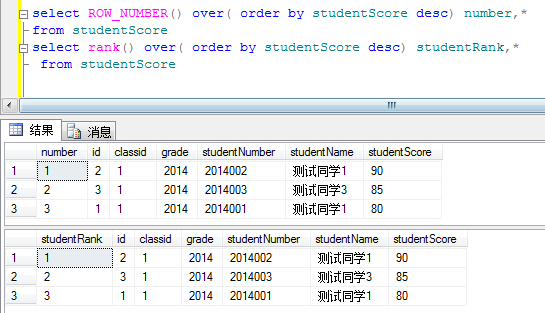
这里发现 ROW_NUMBER()和RANK()怎么一样?因为学生成绩都不一样所以排名和排序一样,下面改一下就会发现区别。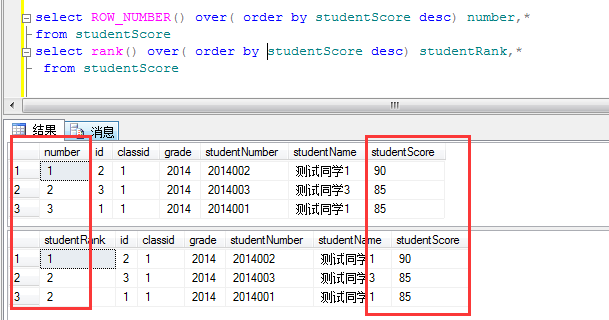
当出现两个学生成绩相同是里面出现变化。RANK()是 1 2 2,而ROW_NUMBER()则还是1 2 3,这就是RANK()和ROW_NUMBER()的区别了
连续排名函数DENSE_RANK()
定义:DENSE_RANK()函数也是排名函数,和RANK()功能相似,也是对字段进行排名,那它和RANK()到底有什么不同那?看例子:
实例: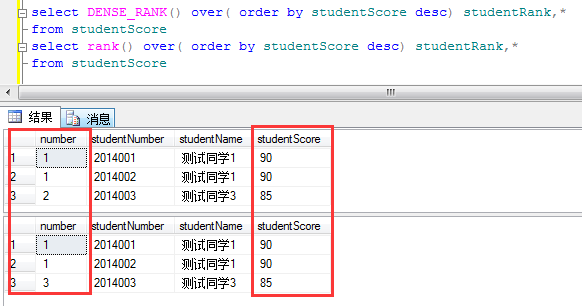
DENSE_RANK()密集的排名他和RANK()区别在于,排名的连续性,DENSE_RANK()排名是连续的,RANK()是跳跃的排名,所以一般情况下用的排名函数就是RANK()。
sum(xxx) over(partition by yyy order by zzz)函数
-- 创建表
create table studentscore
(
name varchar(20) null,
subject varchar(20) null,
score varchar(20) null,
rank varchar(20) null
)
/
comment on column studentscore.name is '姓名'
/
comment on column studentscore.subject is '科目'
/
comment on column studentscore.score is '分数'
/
comment on column studentscore.rank is '科目排名'
/
-- 插入测试数据
insert all
into studentscore values('张三','语文',90,1)
into studentscore values('张三','数学',80,2)
into studentscore values('张三','英语',70,3)
into studentscore values('李四','语文',80,2)
into studentscore values('李四','数学',70,3)
into studentscore values('李四','英语',90,1)
into studentscore values('王五','语文',70,3)
into studentscore values('王五','数学',90,1)
into studentscore values('王五','英语',80,2)
select 1 from dual;
-- 这里的sum_number是各科不断累加后的分数值
select
name,subject,rank,score,
sum(score) over(partition by name order by rank) as sum_number
from studentscore;子查询
将查询的结果作为条件再次查询
查询工资比Abel高的员工
select last_name
from employees
where salary>(select salary from employees where last_name='Abel');
```
*注意事项: 子查询要包含在括号内。将子查询放在比较条件的右侧
题目:返回job_id与141号员工相同,salary比143号员工多的员工姓名,job_id 和工资
```sql
select last_name,job_id,salary
from employees
where job_id=(select job_id from employees where employee_id=141)
and salary>(select salary from employees where employee_id=143);
```
## 在子查询中使用组函数
题目:返回公司工资最少的员工的last_name,job_id和salary
```sql
select last_name,job_id,salary
from employees
where salary=(select min(salary) from employees);子查询中的 HAVING 子句
首先执行子查询,向主查询中的having子句返回结果
题目:查询最低工资大于50号部门最低工资的部门id和其最低工资
select department_id,min(salary)
from employees
group by department_id
having min(salary)>(select min(salary) from employees where department_id=50);
```
## 非法使用子查询的情况
(1)多行子查询使用单行比较符

(2)子查询不返回任何行

## 多行子查询
多行子查询是指返回多行数据的子查询语句。当在 WHERE 子句中使用多行子查询时,必须使用多行运算符(IN、ANY、ALL)
返回多行,使用多行比较操作符
|**操作符**|**含义**|
|---|---|
|IN|等于列表中的任意一个|
|ANY|和子查询返回的某一个值比较|
|ALL|和子查询返回的所有值比较|
体会any和all的区别
在多行子查询中使用 ANY 操作符
题目:返回其它部门中比job_id为‘IT_PROG’部门任一工资低的员工的员工号、姓名、job_id 以及salary
```sql
select employee_id,last_name,job_id,salary
from employees
where salary<any(select salary from employees where job_id='IT_PROG')
and job_id<>'IT_PROG';
```
在多行子查询中使用 ALL 操作符
题目:返回其它部门中比job_id为‘IT_PROG’部门所有工资都低的员工的员工号、姓名、job_id 以及salary
```sql
select employee_id,last_name,job_id,salary
from employees
where salary<all(select salary from employees where job_id='IT_PROG')
and job_id<>'IT_PROG';
```
## 关联子查询
内查询的执行需要借助于外查询,而外查询的执行又离不开内查询的执行,这时,内查询和外查询是相互关联的,这种子查询就被称为关联子查询
在employees表中,使用“关联子查询”检索工资大于同职位的平均工资的员工信息,具体代码如下。
```sql
select e1.last_name,e1.job_id,e1.salary
from employees e1
where e1.salary>(select avg(e2.salary) avgsalary from employees e2 where e1.job_id = e2.job_id) order by job_id
```

```sql
select avg(SALARY) from EMPLOYEES where job_id = 'FI_ACCOUNT';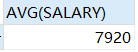
(1)在上面的查询语句中,内层查询使用关联子查询计算每个职位的平均工资。而关联子查询必须知道职位的名称,为此外层查询就使用f.job 字段值为内层查询提供职位名称,以便于计算出某个职位的平均工资。如果外层查询正在检索的数据行的工资高于平均工资,则该行的员工信息会显示出来,否则不显示。
(2)在执行关联子查询的过程中,必须遍历数据表中的每条记录,因此如果被遍历的数据表中有大量数据记录,则关联子查询的执行速度会比较慢。
all与any关键字
select * from 表名 where A{operator}ANY(B);
select * from 表名 where A{operator}ALL(B);A{operator}ANY(B):表示A 与B 中的任何一个元素进行operator 运算符的比较,只要有一个
比较值为true,就返回数据行。
A={operator}ALL(B):表示A 与B 中的所有元素进行operator 运算符的比较,只有与所有元
素比较值都为true,才返回数据行。
例子1: 查询工资同时不等于3000 950 800的员工记录
select * from employees where salary<>all(3000,950,800);
```
例子2: 查询工资为300 或 950 或800的员工记录
```sql
select * from employees where salary=any(3000,950,800);
```
# 分页查询
Oracle中要实现分页查询,需要借助伪列rownum实现(rownum的索引从1开始),语法如下
```sql
/*
需求: 分页查询emps表中的数据, 每页显示5条记录
Oracle中要实现分页查询,需要借助伪列rownum
内层查询中 where rownum<=currentPage*pageSize
外层查询中 where rn>=(currentPage-1)*pageSize+1
*/
-- 查询第一页
select * from
(SELECT e.*,rownum rn from EMPS e where rownum<=5)
where rn>=1;
-- 查询第二页
select * from
(SELECT e.*,rownum rn from EMPS e where rownum<=10)
where rn>=6;
-- 查询第三页
select * from
(SELECT e.*,rownum rn from EMPS e where rownum<=15)
where rn>=11;创建和管理表
查询oracle中由用户定义的表有哪些,列出表名
select table_name from user_tables;查看用户定义了哪些数据库对象
select distinct object_type from user_objects;查看用户定义的表, 视图, 同义词和序列
select * from user_catalog;表名和列名的命名规则
必须以字母开头
必须在 1–30 个字符之间
必须只能包含 A–Z, a–z, 0–9, _, $, 和 #
必须不能和用户定义的其他对象重名
必须不能是Oracle 的保留字
以下的都是不合法的表名和列名
$abc, 2abc, _abc, a-b, a#d
PL/SQL
基本语法(四部分)
declare
-- 变量/记录类型等的声明部分
begin
-- 程序的执行部分
exception
-- 异常的处理
end;示例一: 声明变量
SQL> set serveroutput on -–设置在服务器端输出结果(注意没有分号直接回车)
SQL> ed (注意没有分号直接回车,回车之后就会打开编辑器,在编辑器中编写PL/SQL代码)
declare
v_sal number(8,2):=0;
begin
select salary into v_sal
from employees
where employee_id =123;
dbms_output.put_line('salary: '||v_sal);
end; (写完之后点击OK退出编辑器)
SQL> / (退出编辑器后便回到了命令行界面,输入/后回车执行PL/SQL代码)
-- 输出打印结果
salary: 6500示例二: 声明记录类型,通过记录类型的变量来调用
SQL> set serveroutput on
SQL> ed
declare
-- 声明一个记录类型
type emp_record is record(
v_sal number(8,2):=0,
v_email varchar2(20),
v_hiredate date
);
--声明一个记录类型的变量
v_emp_record emp_record;
begin
select salary,email,hire_date into v_emp_record
from employees
where employee_id=123;
dbms_output.put_line(
' salary:'||v_emp_record.v_sal||
' email:'||v_emp_record.v_email||
' hiredate:'||v_emp_record.v_hiredate
);
end;
SQL> /
-- 输出打印结果
salary:6500 email:SVOLLMAN hiredate:10-10月-97示例三: 声明记录类型,记录类型中字段的类型使用%type动态获取
SQL> set serveroutput on
SQL> ed
declare
-- 声明一个记录类型
type emp_record is record(
v_sal employees.salary%type,
v_email employees.email%type,
v_hiredate employees.hire_date%type
);
-- 声明一个记录类型的变量
v_emp_record emp_record;
begin
select salary,email,hire_date into v_emp_record
from employees
where employee_id=123;
dbms_output.put_line(
' salary:'||v_emp_record.v_sal||
' email:'||v_emp_record.v_email||
' hiredate'||v_emp_record.v_hiredate
);
end;
SQL> /
-- 输出打印结果
salary:6500 email:SVOLLMAN hiredate10-10月-97示例四: 使用%rowtype动态获取所有字段的数据类型
SQL> set serveroutput on
SQL> ed
declare
-- 使用%rowtype
v_emp_record employees%rowtype;
begin
select * into v_emp_record
from employees
where employee_id=123;
dbms_output.put_line(
' salary:'||v_emp_record.salary||
' email:'||v_emp_record.email||
' hiredate:'||v_emp_record.hire_date
);
end;
SQL> /
-- 输出打印结果通过 dict 查看数据库中数据字典的信息
select * from dict;
通过user_tables表可以查看当前登录的用户的所有表的信息
select * from user_tables order by table_name;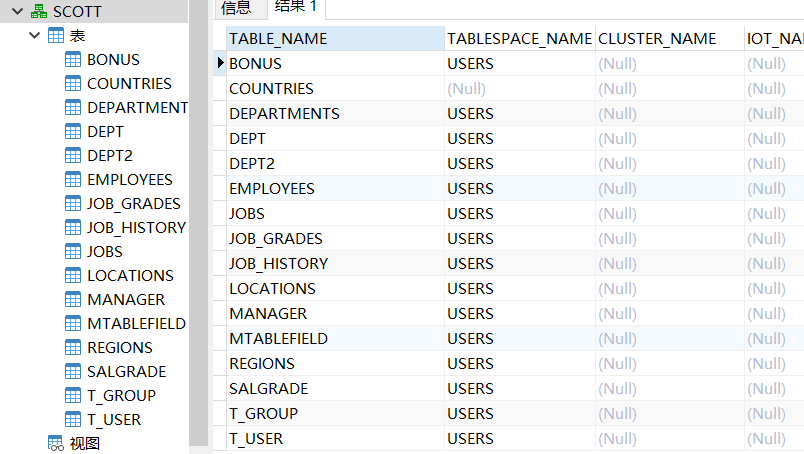
select语句的构成
select {[ distinct | all ] columns | *}
[into table_name]
from {tables | views | other select}
[where conditions]
[group by columns]
[having conditions]
[order by columns]在上面的语法中,共有 7 个子句,它们的功能分别如下:
- select 子句:用于选择数据表、视图中的列。
- into 子句:用于将原表的结构和数据插入新表中。
- from 子句:用于指定数据来源,包括表,视图和其他select 语句。
- where 子句:用于对检索的数据进行筛选。
- group by 子句:用于对检索结果进行分组显示。
- having 子句:用于从使用group by 子句分组后的查询结果中筛选数据行。
- order by 子句:用来对结果集进行排序(包括升序和降序)。
PL/SQL中常见的数据类型
数值类型
NUMBER类型可以存储整数和浮点数(即小数)
NUMBER 类型还可以通过NUMBER(P,S)的形式来格式化数字,其中,参数P 表示精度,参数S表示刻度范围。
精度是指数值中所有有效数字的个数,而刻度范围是指小数点右边小数位的个数,在这里精度和刻度范围都是可选的。
例如: 申明一个精度为4,且刻度范围为2 的表示金额的变量Num_Money,代码如下
Num_Money NUMBER(4,2);
```
### 字符类型
字符类型主要包括 VARCHAR2、CHAR、LONG、NCHAR 和NVARCHAR2 等。这些类型的变量用来存储字符串或字符数据
(1)VARCHAR2用于存储可变长度的字符串,其语法格式为:
```sql
VARCHAR2(maxlength)
```
参数 maxlength 表示可以存储字符串的最大长度, 这个参数值在定义变量时必须给出(因为VARCHAR2 类型没有默认的最大长度)
(2)CHAR用于存储指定长度的字符串,其语法格式为:
```sql
CHAR(maxlength)
```
参数 maxlength 是指可存储字符串的最大长度,以字节为单位(注意1个汉字占两个字节),如果赋给CHAR 类型变量的值不足maxlength,则Oracle会默认在其后面用空格补全


如果长度不够会在数据后面补空格, 这就是定长字符串和变长字符串的区别

(3)日期类型DATE 存储空间占7个字节
(4)布尔类型BOOLEAN 取值只有true false null
## varchar,varchar2, nvarchar,nvarchar2的区别
(1)varchar和varchar2
1)联系
(a)varchar和varchar2的都可以用于存储可变字符串
比如varchar(20),存入字符串'abc',则数据库中该字段只占3个字节,而不是20个字节
(b)size的最大值都是4000而最小值都是1,其值表示字节数
比如varchar(20)表示最大可以存放20个字节的内容
2)区别
(a)varchar2把所有字符都占两字节处理(一般情况下),varchar只对汉字和全角等字符占两字节,数字,英文字符等都是一个字节
比如:VARCHAR2(10),一般情况下最多存放5个汉字,10个字符
(b)VARCHAR2把空串等同于null处理,而varchar仍按照空串处理


*注意:
Oracle中以前的版本有varchar和varchar2两种数据类型,现在很多版本的Oracle只有varchar2这种数据类型了,Oracle官方也建议存储可变字符串用varchar2
MySQL没有varchar2数据类型,只有varchar数据类型
(2)nvarchar,nvarchar2
1)联系
* nvarchar/nvarchar2用于存储可变长度的字符串
* size 的最大值是 4000,而最小值是 1,其值表示字符的个数,而不是字节数
* 这两种类型更适合存储中文
2)区别
* nvarchar中字符为中文则一般按2个字节计算,英文数字等按照一个自己计算
* nvarchar2中所有字符均按照2个字节计算
* nvarchar2虽然更占空间,但是它有更好的兼容性,所有推荐使用
* nvarchar2把空串等同于null处理


使用建议:
在MySQL中存储可变字符串用varchar
在Oracle中存储可变字符串用nvarchar2
VARCHAR2(size)
可变长度的字符串,其最大长度为size个字节;size的最大值是4000,而最小值是1;你必须指定一个VARCHAR2的size;
NVARCHAR2(size)
可变长度的字符串,依据所选的国家字符集,其最大长度为size个字符或字节;size的最大值取决于储存每个字符所需的字节数,其上限为4000;你必须指定一个NVARCHAR2的size;
NUMBER(p,s)
精度为p并且数值范围为s的数值;精度p的范围从1到38;数值范围s的范围是从-84到127;
例如:NUMBER(5,2) 表示整数部分最大3位,小数部分为2位;
NUMBER(5,-2) 表示数的整数部分最大为7其中对整数的倒数2位为0,前面的取整。
NUMBER 表示使用默认值,即等同于NUMBER(5);
LONG
可变长度的字符数据,其长度可达2G个字节;
DATE
有效日期范围从公元前4712年1月1日到公元后4712年12月31日
RAW(size)
长度为size字节的原始二进制数据,size的最大值为2000字节;你必须为RAW指定一个size;
LONG RAW
可变长度的原始二进制数据,其最长可达2G字节;
CHAR(size)
固定长度的字符数据,其长度为size个字节;size的最大值是2000字节,而最小值和默认值是1;
NCHAR(size)
也是固定长度。根据Unicode标准定义
CLOB
一个字符大型对象,可容纳单字节的字符;不支持宽度不等的字符集;最大为4G字节
NCLOB
一个字符大型对象,可容纳单字节的字符;不支持宽度不等的字符集;最大为4G字节;储存国家字符集
BLOB
一个二进制大型对象;最大4G字节
BFILE
包含一个大型二进制文件的定位器,其储存在数据库的外面;使得可以以字符流I/O访问存在数据库服务器上的外部LOB;最大大小为4G字节.
blob、clob、nclob 三种大型对象(LOB),用来保存较大的图形文件或带格式的文本文件,如Miceosoft Word文档,以及音频、视频等非文本文件,最大长度是4GB。 LOB有几种类型,取决于你使用的字节的类型,Oracle 8i实实在在地将这些数据存储在数据库内部保存。 可以执行读取、存储、写入等特殊操作 CLOB(Character Large Object) 用于存储对应于数据库定义的字符集的字符数据。(类似于long类型) BLOB(Binary Large Object) 可用来存储无结构的二进制数据。(类似于row和long row)
### 特殊的数据类型
#### %type类型
使用%TYPE 关键字可以声明一个与指定列名称相同的数据类型,它通常紧跟在指定列名的后面
例: 声明一个与 emp 表中job 列的数据类型完全相同的变量var_job,代码如下。
```sql
declare
var_job emp.job%type;
```
在上面的代码中,若emp.job 列的数据类型为VARCHAR2(10),那么变量var_job 的数据类型也是VARCHAR2(10),甚至可以把“emp.job%type”就看做一种能够存储指定列类型的特殊数据类型。
使用%TYPE 定义变量有两个好处:
第一,用户不必查看表中各个列的数据类型,就可以确保所定义的变量能够存储检索的数据;
第二,如果对表中已有列的数据类型进行修改,则用户不必考虑对已定义的变量所使用的数据类型进行更改,因为%TYPE 类型的变量会根据列的实际类型自动调整自身的数据类型。
示例: 在SCOTT 模式下,使用%type 类型的变量输出employees 表中员工编号为100员工的last_name和job_id

注意: 求select 子句只能返回一行数据,若SELECT 子句返回多行数据,则代码运行后会报错。
#### RECORD类型
oracle中内置的几张有用的表
user_tab_columns表
(1)查询一个表的所有字段名和数据类型
```sql
select COLUMN_NAME,DATA_TYPE from user_tab_columns where TABLE_NAME='大写的表名';
```
# 存储过程
## 创建表的时候如果表已经存在则先drop掉再创建
```sql
-- 创建存储过程
create procedure proc_drop_table_if_exists(p_table in varchar2)
is v_count number(10);
begin
select count(*) into v_count from user_objects where object_name=upper(p_table);
if v_count > 0 then
execute immediate 'drop table' || p_table || 'purge';
end if;
end;
/
-- 调用如果表存在则删除这张表的存储过程
exec proc_drop_table_if_exists('YW_ZJJG_DQB');Oracle错误码大全
ORA-00054资源正忙,要求制定NOWAIT
-- 造成该错误的原因, 一般是由于有人连着数据库, 占用着连接, 所以这时候drop表的时候就会报这个错
-- 解决办法如下
-- 查询目前还占用着的连接的session_id
select i.session_id,o.owner,o.object_name from V$LOCKED_OBJECT i,dba_objects o where i.OBJECT_ID=o.OBJECT_ID;
-- 使用session_id关联V$SESSION表查询其serial#
select t2.username,t2.sid,t2.serial#,t2.logon_time from V$LOCKED_OBJECT t1,V$SESSION t2 where t1.session_id = t2.sid order by t2.logon_time;
-- kill掉这些session会话连接
alter system kill session 'sid,serial#';ORA-00257存档器错误,在释放之前仅限于内部连接
# 登录数据库服务器, 执行如下命令查看磁盘空间的占用情况
df
# 可以看到其中的/archlv路径空间下已经满了, 可以判断是归档日志满了, 需要进行清理
# 切换到oracle用户, 然后执行如下命令先关闭oracle监听, 目的是让归档停止, 然后才能删除归档日志
su - oracle # 注意这里不要少了 - 不然之后执行lsnrctl stop时会报找不到命令
# 停止监听
lsnrctl stop
# 进入RMAN界面(注意不要少了target后面的/符号)
rman target /
# 检测所有归档
crosscheck archivelog all;
# 删除一天前的归档日志, 执行如下命令后输入YES
delete archivelog until time ‘sysdate-1’;
# 退出RMAN界面
exit;
# 使用sysdba用户(数据库管理员用户)登录oracle数据库
sqlplus / as sysdba;
# 关闭oracle
shutdown immediate;
# 重启oracle
startup;
# 退出
exit;
# 重启监听
lsnrctl start
# 上述操作执行完后重新查看磁盘, 可以看到archlv路径下空间已经清理
dfOracle中的其他知识点(待分类)
Oracle某个用户锁表之后删除这个用户
SERIAL# ——会话的串号,当一个会话结束后,另外的会话可能会重用该会话的id号,此时就需要SERIAL#来确定唯一的会话对象。也就是说SID+SERIAL#来确定唯一的会话。
所以删掉一个session会话需要kill这两个值
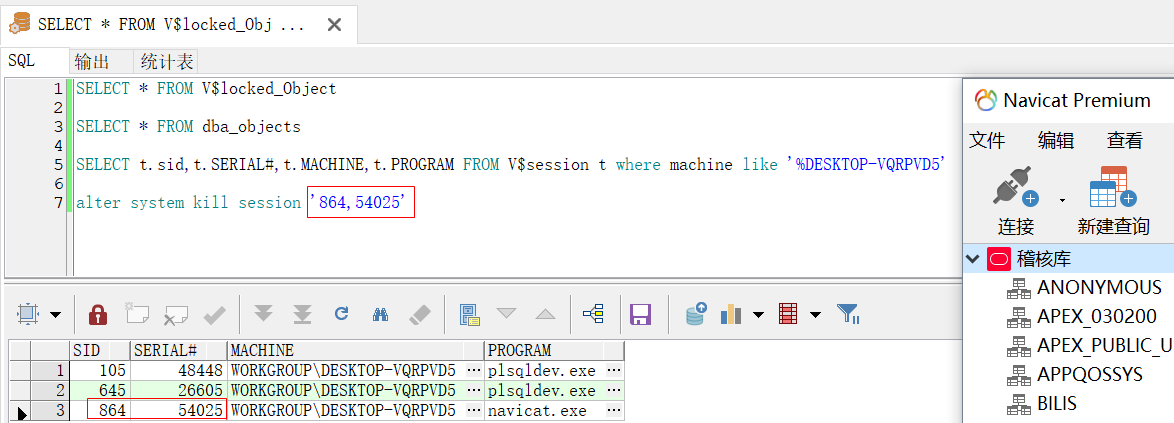
利用V$session,dba_objects和V$locked_Object找到谁给你的对象加了锁
V$locked_Object和dba_objects用object_id可以关联起来,找到dba_objects.object_name,
V$session的Sid和V$locked_object的session_id内联起来,可以从V$session中的machine找到机器名。进而找到机器。
使用alter system kill session ‘sid,serial#’
select V$session.sid,V$session.machine,dba_objects.object_Name
from V$session.sid inner join V$locked_object on V$session.sid=V$locked_object.session_id
inner join dba_objects on dba_objects.object_id = V$locked_object.object_id;V$session会话视图详解
查询或导出所有表及索引
-- 查询表结构(建表语句)
select DBMS_METADATA.GET_DDL('TABLE',t.table_name) from USER_TABLES t;
-- 查询索引
select DBMS_METADATA.GET_DDL('INDEX',idx.index_name) from USER_INDEXS idx;
-- 导出索引
set pagesize 0
set long 90000
set feedback off
set echo off
spool all_index.sql
select DBMS_METADATA.GET_DDL('INDEX',idx.index_name) from USER_INDEXS idx;
spool off;
-- 导出建表语句
set pagesize 0
set long 90000
set feedback off
set echo off
spool all_index.sql
select DBMS_METADATA.GET_DDL('TABLE',t.table_name) from USER_TABLES t;
spool off;


